忖度する人工知能 〜権力にすり寄る計算高い“政治家”:Over the AI ―― AIの向こう側に(20)(7/11 ページ)
今回取り上げるのは「強化学習」です。実はこの強化学習とは、権力者(あるいは将来、権力者になりそうな者)を“忖度(そんたく)”する能力に長けた、政治家のようなAI技術なのです。
「5並べ」の強化学習プログラムですら、設計できなかった
「なーんだ、こんな簡単なら、私でもチョイチョイっと作れるな」と ―― 私は、「5並べ」の強化学習プログラムを作ろうと、頭の中でコーディングを始めました(私は、囲碁も将棋もマージャンも、ゲームと名前のつくもののほとんどのルールを知りませんので)。
ところが、これが「全く」ダメダメだったのです。強化学習の「4行」は、問題なかったのですが、別のところで、どうしようもないことが分かってきたからです。

つまり、強化学習は、その仕組みよりも、その環境(「状態」と「行動」)を定義すること(正確に言うと、「状態」と「行動」のパターン数を極限まで小さくすること)が恐しく難しいのです。
というか、その環境の定義に成功した人だけが、「将棋」や「囲碁」のマスターを倒すプログラムを作ることができた、ということが、ようやく私にも分かってきました*)。
*)以前後輩に「江端さん、大切なのは『学習プロセス』ではなく『局面の設計』ですよ」と言われた意味が、今回、ようやく理解できました。
これを考えていくと、なぜ、私たちが「強化学習」を、義務教育や高等教育過程で使わないのかは、明らかです。

つまり、私たちは、私たちの人生(の局面(状態と行動))を設計することができない上に、強化学習のように、数千〜数億の回数で人生をやり直すことができないのです。
でも、本当にそうかな? と思い、もう少しつっこんで考えてみました。
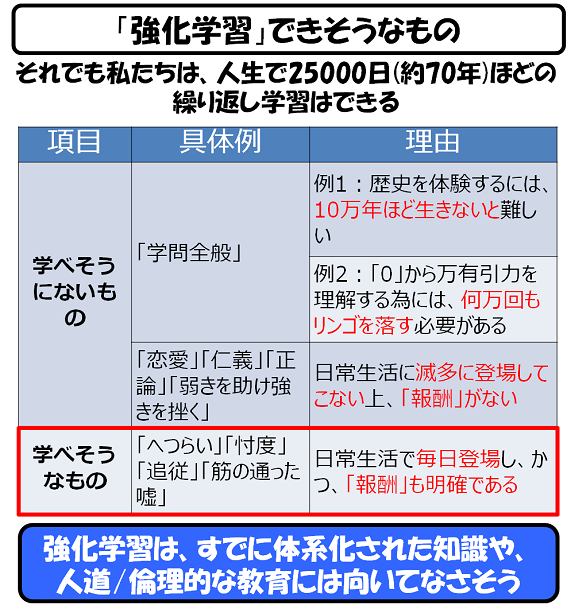
人生2万5千日もあれば、そこそこの強化学習はできそうなのですが、毎日登場するような事項にしか、使えそうにありません。
まあ、毎日登場するようなことといえば、上記の様な内容になってしまう訳でして、つまつところ、「強化学習を、義務教育や高等教育の代替とすることは無理」という結論になる訳です。
Copyright © ITmedia, Inc. All Rights Reserved.