Arm MLプロセッサ、明らかになったその中身:モバイル機器でのエッジAI向け(3/5 ページ)
2018年8月に開催された「Hot Chips 30」では、Armの「ML Processor(MLプロセッサ)」の中身が明らかになった。その詳細を解説する。
Convolutionを担うMAC Engineの中身
さてConvolutionそのものはひたすら乗算と加算である。これを担うのがMAC Engineであり、やはり想定通り1つのMAC Engineで256Ops/Cycleの処理が可能とされる(図7)。

図7 MACエンジンの利用率が重み(1×1なのか3×3なのか5×5なのか)によって変わってくるのはまぁ当然ではある。これに応じてDatapath Gatingも施しているという話は後でも出てくる 出典:Arm(クリックで拡大)
そのMAC Engineは8つのDP(Dot Product)ユニットがあり、1つのDP UnitはSIMD方式で16演算を同時に行える。先のページで2×8×16という計算があったが、この8×16は8つのUnit×16演算を指す。で、DP Unitは乗算だけを行い、そのあと下側のAccumulatorsで加算を行う形になると思われる。
これを分離したのは、重みが4×4構成なら、ちょうど1つのDP Unitで1cycleで処理できるが、あまり4×4という構成は使われないからだろう。1×1なら同時に16個分を計算できるが、3×3だと多少余るし、逆に5×5とか7×7だと1cycleで処理しきれない。例えば3×3だとMAC Unit全体で14回分の処理が1cycleで可能だが、この場合いくつかの処理は2つのDP Unitに跨いで処理されることになる(図A)。あるいは5×5とかになると図Bのように、2つ以上のDP Unitにまたがる形で処理されることもある。

こうなると加算の方はDP Unit単位で処理するのは不効率である。そんなわけでAccumulatorの方は、任意のデータ幅で集計が可能な、128演算の巨大SIMD加算器という構成になっていると思われる。ちなみに図7にもあるが、入力データそのものは8bit Integerながら、この乗算と加算に関しては内部32bitで演算を行い、結果をまた8bitにして戻すという形の実装になっている模様だ。加算と乗算を1cycleでそれぞれ128個ずつ行える結果が、256Ops/cycleというわけである。
面白いのは、入力特徴マップに関してはMAC Engineに直結ではなく、Broadcast Network経由になることだ(図9)。

 図8(左):さすがに1つのConvolutionについて、複数のCompute Engineを跨いで処理するという事は考えていないようだ。それをやると、Data Pathの負荷が猛烈に増えるためだろう/図9:図6に"Input Feature Maps(IFMs) are interleaved across all SRAM banks"とあるのがこれの事 出典:Arm(クリックで拡大)
図8(左):さすがに1つのConvolutionについて、複数のCompute Engineを跨いで処理するという事は考えていないようだ。それをやると、Data Pathの負荷が猛烈に増えるためだろう/図9:図6に"Input Feature Maps(IFMs) are interleaved across all SRAM banks"とあるのがこれの事 出典:Arm(クリックで拡大)そもそも入力特徴マップは結構大きくなりがちだし、例えば図Cのように5×5の入力特徴マップに4×4の重みを掛けて2×2の出力特徴マップを得るというケースで、必ずしも畳み込み演算が一つのCompute Engineで完結するという保証もない。
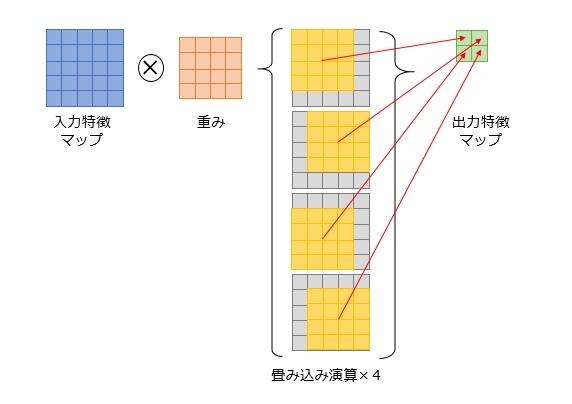
複数のCompute Engineに跨いで畳み込み演算を分散する(畳み込み演算一つ一つは、Compute Engine1個の中で完結する様にしないと効率が悪いだろう)ケースでは、入力特徴マップは全てのCompute Engineから参照される可能性がある。これをBroadcastで解決するというあたりが、ちょっと独特ではあるが、賢いやり方である。逆に重みの方はBroadcastを使わずに、各Compute EngineローカルのSRAMから直接読む方式である。

図Cは、全てのCompute Unitが同一の層を処理するという前提の話であるが、例えばCompute Unit 0〜3が第1層の、4〜7が第2層の処理をするなんて場合はそもそも重みが全く変わってくるから、これは独立して持たせたほうが賢明という判断なのだろう。こうして加算が終わった結果は、次にProgrammable Layer Engineに渡されることになる(図11)。
ちなみにこのMAC Engine、POP IPが16nmおよび7nmプロセス向けにわざわざ提供されるとしている(図12)。ここ(と、次のProgrammable Layer Engine)が一番消費電力が多いだけに、これは納得できるところだ。


Copyright © ITmedia, Inc. All Rights Reserved.