正データと正信頼度の情報だけで分類境界を学習:負のデータがなくても大丈夫
理化学研究所(理研)の研究チームは、人工知能(AI)を用いた機械学習の分類問題で、正のデータとその信頼度(正信頼度)情報だけで、分類境界を学習できる手法を開発した。
あらゆる分類モデルと合わせ可能な学習アルゴリズム
理化学研究所(理研)革新知能統合研究センター不完全情報学習チームの石田隆研修生とGang Niu(ガン・ニュー)研究員および、杉山将チームリーダーらの研究チームは2018年11月、人工知能(AI)を用いた機械学習の分類問題で、正のデータとその信頼度(正信頼度)情報だけで、分類境界を学習できる手法を開発したと発表した。
AIを用いた機械学習の分類問題では、正のデータと負のデータを分離するための境界をコンピュータに学習させる。分類境界を学習すると、未知のデータであってもコンピュータ側で「正」か「負」かを判断できるようになるという。
これまで分類技術を活用すると、正のデータと負のデータを事前に用意しなければならなかった。ところが、商品の購買予測などで、他社商品を購入した例など、負データを収集することは極めて難しかった。また、サービス契約の解除などから個人情報にかかわる過去データを削除しなければならないケースも考えられるという。
そこで研究チームは、正のデータしか入手できないケースでも、「正のデータがどれだけ正しいか」という信頼度の情報があれば、データを分類できるのではないかと考えた。例えば、データの信頼度が90%だと、「正のデータ90%」「負のデータ10%」と重み付けした2つのデータに分解することができる。この作業を全てのデータに対して行えば、「正」と「負」のデータが存在するため、従来の学習アルゴリズムを適用することが可能になる。ところが、この方法では正しい分類境界から離れた位置にある境界を学習してしまうことが実験により分かったという。
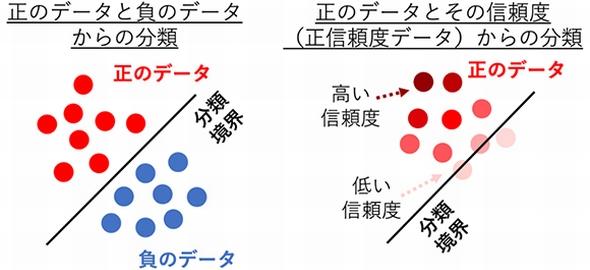
この課題に対して研究チームは、正と負のデータが共存する時に、コンピュータが最小化していた分散リスクの数式を再構成した。正のデータとその信頼度のデータで書き直す式変形を行ったところ、分類リスクが正のデータとその信頼度だけで表現されることが分かった。再構成した分類リスクを最小化することで、正のデータとその信頼度だけでも、精度よく学習できるようになった。理論解析により、望ましい性質を持つ方法であることも証明した。開発した学習アルゴリズムは、線形モデルや深層学習モデルなど、あらゆる分類モデルと容易に組み合わせることができるという。
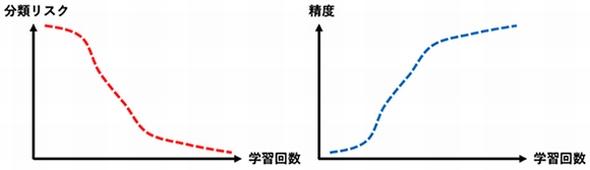
ベンチマークとなるデータセットを用いた実験でも、正のデータとその信頼度だけでコンピュータがうまく学習できることを示した。多くのデータセットに対して、開発した手法が他の手法に比べて、最も優れた分類精度を示すことも分かった。
研究チームは、多くの分野において正信頼度の情報に基づく分類技術が適用できるとみており、今回の実験で用いたプログラミング言語「Python(パイソン)」によるアルゴリズムの実装コードをWeb上で公開する予定だ。
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
 理研、パルス電流で超電導状態の制御に成功
理研、パルス電流で超電導状態の制御に成功
理化学研究所(理研)の研究チームは、パルス電流を用いて「超電導状態」の生成と消去に成功した。書き換え可能な超電導量子コンピュータ向け回路の実現につながる可能性が高い。 理研と東レ、衣服に貼り付けられる有機太陽電池を開発
理研と東レ、衣服に貼り付けられる有機太陽電池を開発
理化学研究所(理研)と東レは2018年4月17日、高い耐熱性と変換効率を兼ね備えた超薄型有機太陽電池の開発に成功したと発表した。e-テキスタイルへの応用や、車載やウェアラブル機器の電源として活用が期待できるという。 外部磁場がなくても磁気渦を生成、理研らが発見
外部磁場がなくても磁気渦を生成、理研らが発見
理化学研究所(理研)らによる国際共同研究グループは、磁気渦の新しい生成機構を発見した。磁気渦を情報担体とする磁気記憶素子の実現につながる研究成果と期待されている。 SiC-MOSFETを活用した4象限電源、理研などが開発
SiC-MOSFETを活用した4象限電源、理研などが開発
理化学研究所(理研)とニチコンらの共同研究グループは、SiC(炭化ケイ素)-MOSFETを用いることで、高い出力と安定性を両立させつつ、出力電流の方向や大きさを広い範囲で変更できるパルス電源を開発した。 教師データなしで声を聞き分ける脳型学習アルゴリズム
教師データなしで声を聞き分ける脳型学習アルゴリズム
理化学研究所(理研)は、教師データがなくても、ノイズが混じった信号源から特定の人の声を聞き分けることができる「脳型学習アルゴリズム」を開発した。 シリコン量子ドット構造で高精度量子ビット実現
シリコン量子ドット構造で高精度量子ビット実現
理化学研究所らの研究グループは、シリコン量子ドット構造で世界最高レベルの演算精度を実現した電子スピン量子ビット素子を開発した。シリコン量子コンピュータの開発に弾みをつける。