ChatGPTは怖くない 〜使い倒してラクをせよ:踊るバズワード 〜Behind the Buzzword(18)(6/11 ページ)
ある日突然登場し、またたく間に世間を席巻した生成AI「ChatGPT」。今や、ネットでその名を聞かない日はないほどです。このChatGPTとは、一体何なのか。既に数百回以上、ChatGPTを使い倒している筆者が、ChatGPTの所感をエンジニア視点で語ってみたいと思います。
ChatGPTは「何も考えていない」
今回は、これを英語学習のパラダイムで説明してみましょう。

ここでは、
- ChatGPT君を育てる教師である「あなた」
- あなたの弟子の教育実習生の「リ・ワード(Reward)さん」
- まだ英語を全く知らない小学1年生の「ChatGPT君」
の3人を登場させます。
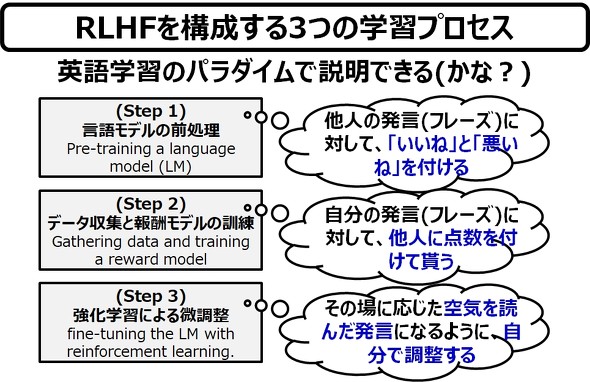
(Step 1) 言語モデルの前処理
ここでは、小学1年生のChatGPT君が、英語で書かれた膨大な他人のメッセージをひたすら読んだり、聞いたりします。ChatGPT君は、もちろん、その英語のメッセージの意味が分かりませんが、教師であるあなたは、その一つ一つのメッセージに、「いいね」「悪いね」と評価を付けて、ChatGPT君に強制的に教えこみます。
ちなみに、ChatGPT君は、英語のフレーズの意味を、全く理解しておりません(というか、ChatGPT君は、自分が英語を学習しているという自覚すらありません)が、とにかく、先生であるあなたの言うことを素直に聞いて、英語のフレーズと対応付けて「いいね」と「悪いね」を覚えます。
(Step 2)データ収集と報酬モデルの訓練
あなたは、ChatGPT君に対して、1つのフレーズを与えて、そこから4つの言い換えのフレーズを言うように命じます。ChatGPT君は、(Step 1)で覚えたフレーズと、あなたに教えてもらった「いいね」と「悪いね」を思い出して、4つのフレーズを捻り出します。なお、ChatGPT君は、この段階においても自分が、英語のフレーズをしゃべっているという自覚がありません。あなたの言われた通りのフレーズを書き出す、または、音声信号を発しているだけです。
あなたは、この4つのフレーズに対して、あなたが良いと思うものから順に、1番、2番、3番、4番と順番を付けていきます。そして、ChatGPT君に対して、「なるべく1番のフレーズを使うよう」に言い聞かせます。ChatGPT君は、素直にあなたの言うことを聞いて、できるだけあなたの言う通りの英語をしゃべるようになります。そして、しつこいですが、ChatGPT君は、この段階においても自分が、英語のフレーズをしゃべっているという自覚がありません。
(Step 3)強化学習による微調整
こうして、ChatGPT君を訓練していたあなたは、そのうち、その作業が面倒くさくなってきました。そして、あなたの近くにいた、教育実習生のリ・ワードさんに、「私がやってきたこと、見てきたよね。後は、あなたが私の代わりにやってちょうだい」と言って、ChatGPT君の教育を、リ・ワードさんに丸投げして帰宅してしまいます。
リ・ワードさんは、あなたがChatGPT君に何を施していたのかを全く理解していませんが、あなたとChatGPT君のやりとりを見続けていたので、あなたのマネをすることができました。ですので、リ・ワードさんは、自分が「リ・ワードである」とは言わず、あなたのフリをして、ChatGPT君の訓練を延々と続けました。
こうして、ChatGPT君は、世界中の人のメッセージに対して、そのメッセージに適したメッセージを返事することができるようなり、無事に世界デビューを果たすことができるようになりました。しかし、ChatGPT君は、この段階においても自分が何をしているのか、全然分かっていません。
ChatGPT君は、今もなお、何も考えていません。あなたに言われた「いいね」「悪いね」と「4段階のランク」を、ただひたすら、忠実に守っているだけです。
3人の話を技術的な話に落とし込んでみる
さて、ここからは、上記の教師である「あなた」と、あなたの影武者として働き続ける「リ・ワードさん」と、あなたの教育対象である「ChatGPT君」の話を、技術的な話に落とし込んて語ってみましょう。
ChatGPTの本体は、ニューラルネットワークです。ニューラルネットワークは、深層学習によって、膨大な下図の非線形の因果関係を覚えることができます(私のコラムなどで、ご確認ください)。
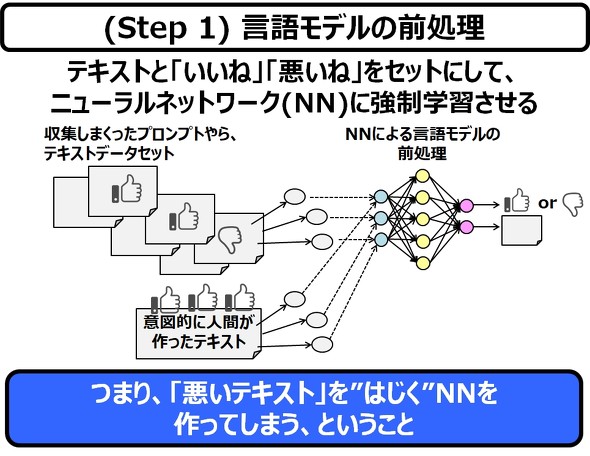
とにかく、駄文、悪文、良文、関係なく、ニューラルネットワークに、その情報を叩き込み、単純に「いいね」と「悪いね」を出力する”だけ”の学習を施しまくります。
学習後、このニューラルネットワークに、実際のフレーズを入力すると、まずまずの文章を複数作り出します。そのフレーズは人間様が丹念にチェックします(想像を絶する大変さだと思います)。
そして、それと同時に、その人間様と同じように振る舞う別のニューラルネットワーク「報酬モデル(Reward Model)」も作っておきます。これが、人間抜きの教育を行う準備となります。

さて、ここから最終段階に突入します。ここから、人間のフリをする「報酬モデル」が介入しながら、ChatGPTのニューラルネットワークの強化学習を継続します。
ただ、この学習を「報酬モデル」に任せ続けると、ChatGPTは、最初の自分の状態を完全に忘れてしまいます。これを防止するために、KL(カルバック・ライブラー)予測というメカニズムを使って、初心を忘れないように、学習のし過ぎ(過学習)にブレーキをかけます。

ちょっと(かなり)混乱していると思いますので、ここで、最初の英語学習のパラダイムと併せて、いったん整理しましょう。
・初期言語モデル
→ 膨大な文章を覚えたばかりの初期状態の「初期言語モデル」であり、初々しいピカピカのChatGPT君である
・調整された言語モデル
→ 人間(あなた)と報酬モデル(リ・ワードさん)によって訓練され尽くした、プロフェッショナルなChatGPT君である
・報酬モデル(Reward Model)
→ 人間(あなた)がChatGPT君の教育の様子を見て、それをマネてあなたの代わりをする、教育実習生の「リ・ワードさん」である
・あなた
→初期段階のChatGPTに、「いいね」「悪いね」「4段階の採点」を付ける、生身の(重労働の)人間である
こうして、ChatGPT君は、「あなた」と「リ・ワード」さんに鍛えられて、一人前のChatGPTとしてデビューを果たすわけです。
なお、しつこいほど繰り返しますが、ChatGPT君は、『何も考えていません』。「あなた」と「リ・ワード」さんに言われたことを、淡々とやっているに過ぎません。
Copyright © ITmedia, Inc. All Rights Reserved.