機械学習を5倍に高速化、FP32と同等精度を9ビットで:産総研と東大の共同研究
産業技術総合研究所は2018年5月29日、東京大学と共同で、機械学習の学習処理に必要な演算量を削減する計算方式と演算回路を考案したと発表した。今回提案した計算方式では、同研究グループが考案した9ビットの数値表現を用いていることがポイントで、単位消費電力あたりの処理能力が従来方式と比較して約5倍まで向上するという。
産業技術総合研究所は2018年5月29日、東京大学と共同で、機械学習の学習処理に必要な演算量を削減する計算方式と演算回路を考案したと発表した。今回提案した計算方式では、同研究グループが考案した9ビットの数値表現を用いていることがポイントで、単位消費電力あたりの処理能力が従来方式と比較して約5倍まで向上するという。

学習処理では、FP32(32ビット浮動小数点)かFP16の数値表現を用いることが多い。一般的に、大きな数値表現を利用すると精度が向上する一方で、演算回路の規模が大きくなり、処理時間や消費電力が増大する。また逆に、小さな数値表現を利用すると回路規模は小さくなり処理時間や消費電力は減少するが、精度は悪化する。
今回の研究で同グループは、学習で現れる数値範囲を解析。限られたビット数で精度を維持できる数値表現と、ビット数が小さくても学習で多用される積和演算が正確に実行できる計算方式を考案した。
9ビット表現で乗算回路と読み出しエネルギーを大幅削減
IEEEで定義されるFP32は、符号1ビット、指数部8ビット、仮数部23ビットで構成されるのに対し、今回提案する9ビット数値表現は、符号1ビット、指数部5ビット、仮数部3ビットで構成される。
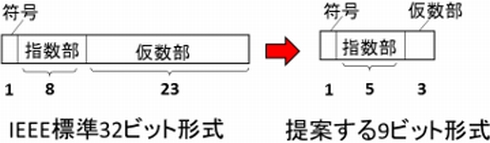
FP32の場合、乗算回路は全演算回路の約80%を占めるほど大きな回路となる。しかし、9ビット表現では乗算回路がFP32と比べて30分の1程度となる。さらに、演算回路への読み出しについても必要エネルギーを約4分の1まで削減できるという。
乗算は仮数部3ビット、加算は仮数部23ビットで精度を維持
また、9ビット表現を利用するにあたって演算回路にも工夫を凝らした。機械学習において推論の精度は、「情報落ち」の発生など加算の演算精度に大きく影響を受ける。本研究では、加算処理で仮数部を23ビットとして演算することにより精度劣化を防いだ。加算回路で仮数部を23ビットに拡張しても、演算回路全体の大きさに影響は少ないという。
これら技術を活用し、同グループが今回開発した積和演算回路では、まず2つの入力を9ビット表現で読み込み乗算する。次に、乗算結果の仮数部を23ビットへ変換、ビットシフト処理を行った後、23ビットで加算を行う。加算結果は再び9ビット表現に変換し出力する。
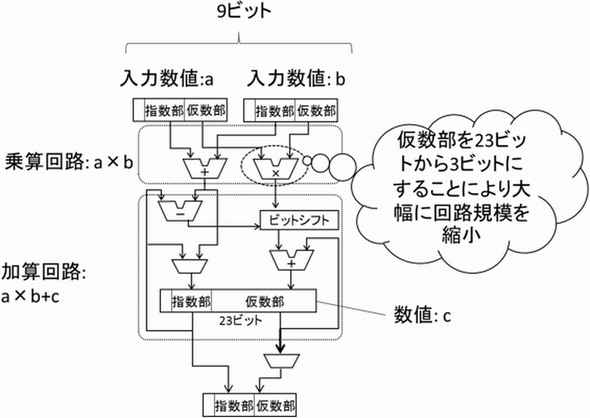
この計算方式と回路について、同グループはシミュレーションによって推論精度や消費電力を推定。FP32を用いた場合と比べて、9ビット表現を用いて生成したモデルによる推論精度の劣化は2%程度に抑えられた。一方、9ビット表現では回路規模を従来比5分の1程度に縮小できると推定され、消費電力も5分の1程度に低減できるという。これにより、従来精度による学習と同一規模のハードウェアを用いた場合には約5倍の高速化を実現できるとする。
同グループは本技術について、FPGAや機械学習専用プロセッサで利用されることを期待するとしている。また、機械学習を行う問題によっては8ビット表現でも十分な精度で学習が可能なことが判明しているとして、今後は多くの問題で本技術の有効性を試験すると同時に、ハードウェアを試作して実現可能性の検証と実用化を進めるとした。
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
 NVIDIAが解説するディープラーニングの基礎(前編)
NVIDIAが解説するディープラーニングの基礎(前編)
エヌビディアは2018年4月24日、ディープラーニングに関するセミナー「NVIDIA Deep Learning Seminar 2018」を東京都内で開催した。本稿では、セッション「これから始める人のためのディープラーニング基礎講座」から、ディープラーニングの歴史や概要、学習の流れについて紹介する。 NVIDIAが解説するディープラーニングの基礎(後編)
NVIDIAが解説するディープラーニングの基礎(後編)
エヌビディアは2018年4月24日、ディープラーニングに関するセミナー「NVIDIA Deep Learning Seminar 2018」を東京都内で開催した。本稿では、セッション「これから始める人のためのディープラーニング基礎講座」から、各種ニューラルネットワークやその応用例、ディープラーニングフレームワークの概要について紹介する。 富士通のAIプロセッサ、演算精度とμアーキに工夫
富士通のAIプロセッサ、演算精度とμアーキに工夫
富士通は、同社のプライベートイベント「富士通フォーラム2018 東京」(2018年5月17〜18日、東京国際フォーラム)で、ディープラーニング処理に特化したプロセッサ「DLU(Deep Learning Unit)」を展示した。競合となる既存のアクセラレーターと比較して、10倍の電力性能比を実現するとしている。 機械学習の時間を100分の1へ、インテルAIの戦略
機械学習の時間を100分の1へ、インテルAIの戦略
インテルは2016年12月9日、米国で開催した人工知能(AI)に関するイベント「AI Day」で発表した内容をもとに、AI事業に向けた戦略について説明会を開催した。2016年8月に買収したNervana Systemsの技術をベースとしたAI製品群を展開し、2020年にマシンラーニング(機械学習)における時間を現行の最速ソリューションと比較して100分の1に短縮することを目指す。 IMEC、全く新しいAIチップの情報を公開
IMEC、全く新しいAIチップの情報を公開
IMECはベルギーで開催された年次イベント「IMEC Technology Forum」でAI(人工知能)や機械学習に関連した新しい概念のチップに関する開発成果を公表した。 組み込み機器側に学習機能を搭載、高精度に推論
組み込み機器側に学習機能を搭載、高精度に推論
三菱電機は、組み込み機器に実装できる「ディープラーニングの高速学習アルゴリズム」を開発した。「コンパクトな人工知能」と組み合わせることで、車載機器や産業用ロボット側に学習機能を搭載することができ、より高精度の推論を行うことが可能となる。