スマホでAI処理を行うプロセッサアーキテクチャ:実効効率は最大26.5TOPS/W
東京工業大学は、高度なAI処理をスマートフォンなどで実行できる「プロセッサアーキテクチャ」を開発した。試作したチップの実効効率は最大26.5TOPS/Wで、世界トップレベルだという。
TSMCの40nmプロセスでチップを試作
東京工業大学科学技術創成研究院の本村真人教授と安藤洸太特任助教は2021年8月、高度なAI処理をスマートフォンなどで実行できる「プロセッサアーキテクチャ」を開発したと発表した。試作したチップの実効効率は最大26.5TOPS/Wで、世界トップレベルを達成した。
本村教授らは、新エネルギー・産業技術総合開発機構(NEDO)が進める開発プロジェクト「高効率・高速処理を可能とするAIチップ・次世代コンピューティングの技術開発」において、高効率の畳み込みニューラルネットワーク(CNN)推論処理をエッジ機器で実行できるプロセッサアーキテクチャの開発に取り組んでいる。
CNN推論処理をスマートフォンやロボットなどのエッジ機器で利用する方法として、CNNの枝刈り(プルーニング)などがこれまで提案されてきた。この方法だと、計算量とメモリ容量を削減することはできるが、メモリへのアクセスが不規則になり、並列処理の計算効率が低下するという課題があった。
これに対し本村教授らは、チャネル間畳み込みと入力データのチャネル内平面シフトを利用して畳み込みの積和演算を行うことが効率的であることを明らかにし、並列演算アレイとデータ整形機構を中核としたアーキテクチャを開発した。
本村教授らはまず、CNNの並列演算における効率改善に取り組んだ。CNNは「畳み込み層」や「プーリング層」「全結合層」などで構成されている。畳み込み層における畳み込み演算は、入力活性とカーネル群から複数チャネルの出力データを生成する積和演算の繰り返しからなる。依存関係がない入力チャネル内のピクセル位置と出力チャネル方向の座標軸を選択すると、積和演算をそれぞれの行と列で、独立の積(直積)と和の計算に分離できる。これによって、データ再利用性を高く保つ並列計算が可能になり、計算効率が高くなる。特に、カーネルサイズ1×1のチャネル間畳み込みで、その効果が大きくなるという。
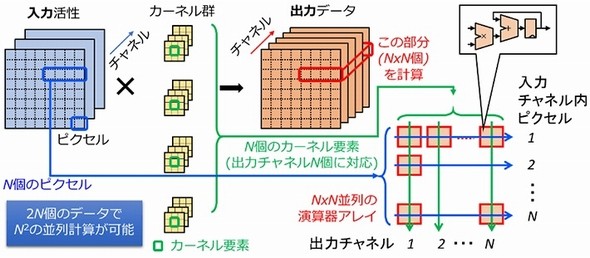
次に検討したのが計算効率のアルゴリズム改善である。あらゆる畳み込み演算が、入力データのチャネル内平面シフトとカーネルサイズ1×1のチャネル間畳み込みの組み合わせに分解できることに着目。特に、チャネル内とチャネル間にカーネルを分離して軽量化した畳み込み演算では、入力データのチャネル内平面シフトを扱う整形機構によって、高いデータ再利用率で処理できることが分かった。しかも、畳み込みカーネルをカーネル要素の座標に合わせて枝刈りをすることで、計算効率のさらなる向上が可能になったという。
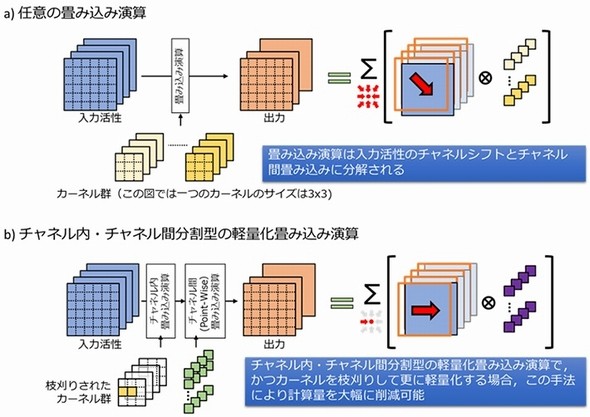
さらに既存のCNNモデルを変形し、同一座標のカーネル要素を優先して枝刈りをする学習アルゴリズムを構築した。開発したアルゴリズムは、既存の学習済みモデルに対し連続的にカーネル要素数を減らしながら再学習を行う。求める処理時間や効率と認識精度によって、スパース率のトレードオフ点を任意に選択することが可能だという。
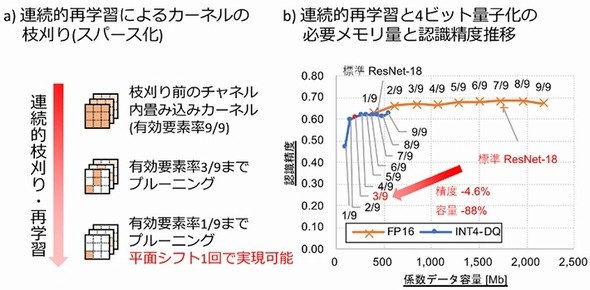
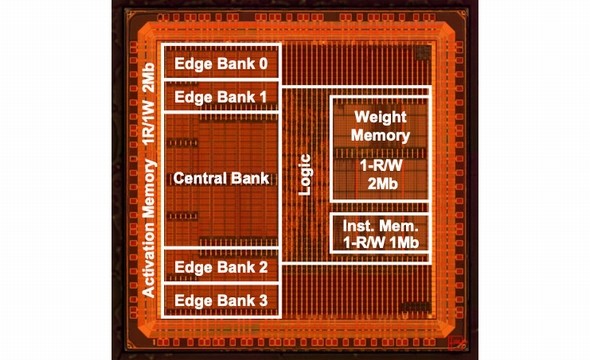
本村教授らは、開発したアーキテクチャに基づく試作チップを、TSMCの40nmプロセスで製造し、その特性を評価した。並列演算アレイサイズは32×32で、活性値・係数値には4ビット固定小数点(INT4)量子化を採用した。このチップは、最大534MHz、1.1Vの動作環境で、電力消費は400mW以内となった。カーネル要素数を9分の1まで枝刈りをした後のスパース化した不要カーネル要素の省略を考慮すれば、実効効率は26.5TOPS/Wに相当するという。これは、エッジ機器向けCNN推論プロセッサとして、世界トップレベルの数値になる。
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
 日本大学ら、磁性物質の量子性を圧力によって制御
日本大学ら、磁性物質の量子性を圧力によって制御
日本大学などの研究グループは、1万気圧以上の高圧力中において、鎖状の磁性体である三塩化セシウム銅の磁気測定と理論モデルによる解析を行い、圧力によって量子性の強さが制御できることを実証した。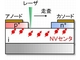 量子センサーのスピン情報、電気的読み出しに成功
量子センサーのスピン情報、電気的読み出しに成功
東京工業大学と産業技術総合研究所(産総研)の共同研究グループは、ダイヤモンド量子センサーのスピン情報を、電気的に読み出すことに成功した。感度が高い集積固体量子センサーの実現が期待される。 ギャップ長20nmのナノギャップガスセンサーを開発
ギャップ長20nmのナノギャップガスセンサーを開発
東京工業大学は、抵抗変化型ガスセンサーの電極間隔(ギャップ長)を20nmと狭くしたナノギャップガスセンサーを開発した。ギャップ長が12μmの一般的な酸素ガスセンサーに比べ、約300倍の応答速度を実現した。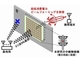 東京工大、電源不要のミリ波帯5G無線機を開発
東京工大、電源不要のミリ波帯5G無線機を開発
東京工業大学は、無線電力伝送で生成される電力で動作させることができる、「ミリ波帯5G中継無線機」を開発した。電源が不要となるため基地局の設置も容易となり、ミリ波帯5Gのサービスエリア拡大につながるとみられている。 基板に有機化合物を自在に塗布する技術を開発
基板に有機化合物を自在に塗布する技術を開発
東京工業大学は、水中で電気刺激を与え、色素などの有機化合物を自在にプラスチックやガラスといった基板上に塗布する技術を開発した。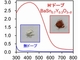 新合成法でペロブスカイト型酸水素化物半導体開発
新合成法でペロブスカイト型酸水素化物半導体開発
九州大学と東京工業大学、名古屋大学の研究グループは、長波長の可視光に応答するスズ含有ペロブスカイト型酸水素化物半導体を合成することに成功した。安価な鉛フリー光吸収材料を合成するための新たな手法として期待される。