光トランシーバーのForm Factorの新動向(8) 〜CPO/NPOと新しいデータセンター:光伝送技術を知る(19) 光トランシーバー徹底解説(13)(4/4 ページ)
前回の記事でお問い合わせを多くいただいたのが、新しい規格と紹介したNPO(Near Package Optics)と、CPO(Co-packaged Optics)が適用されると想定した新しい適用システムとして紹介したDisaggregated Systemに関してであった。今回はそれを少し詳しく触れてForm Factorの締めくくりとしたい。
AI/ML/HPCを中心としたデータセンターはどう進化?
ところで、先に述べたAI/ML/HPCを中心としたデータセンターは、どのような姿に進化していくのだろうか。恐らく、Rack-Scaleを超えたDisaggregated Systemとなる可能性がある。しかも、種類の異なるアルゴリズムに特化したGPUに対応しなければならない。さらに、10倍、100倍と計算速度の新記録が次々と更新される革新の時代では、将来開発されるGPUやアルゴリズムに対応可能なアーキテクチャを開発するのは容易ではない。
最近話題のクラウドネイティブなGPU PODの例として、図7にNVIDIAのAIインフラ向けユニバーサルシステム「DXG A-100」を示す。

8台のGPUアクセラレーターが搭載されている。各GPUは6台のNVSwitchで接続され、600GB/s(単純に8倍として4.8Tb/s)のデータ交換が可能だという。このDGX A-100は最大16台のGPU(2 Box)がNVSwitchを介して結合できるということだ。
一方、後方には各GPUに対して1台のNICカードが搭載されている。これにより各GPUはホストCPUを介することなく、直接Box外と直接データを送受信できる。インタフェースはネットワークサイドが200Gbit/sのHDR InfiniBand(あるいはEthernet)であり、16本のPCIe Gen 4(31.5Gbit/s)により、ダイレクトにGPUのメモリにアクセスする(DMA: Direct Memory Access)。
より多くのGPUを接続したDGX Clusterでは、後方のNICカードの光トランシーバーがFat Tree (Clos) Switch Networkに接続されるという。GPU間を直接接続できるのだ。
大容量ストレージサーバにも同Networkを介して接続される。NICカードの1枚はホストCPU用で、前方にあるSSDを介してメインストレージデータをGPUに入出力できる。特に学習において、同じデータを繰り返し計算に使用することで精度を上げるために必要だとしている。SSD(NVMemory)の帯域は3.84TB/sだそうだ。
このBoxを40台、320 GPU接続したSuperPODと呼ばれるシステムをベースにした「Selene」が、スーパーコンピュータの性能ランキング「TOP500」(2021年11月版)で6位を獲得した。また、NVIDIAのGPU「A100」を400基以上使用したHPEの「Cray EX235n」ベースのスパコン「Perlmutter」は同5位となっている。1位の富岳に比べ7分の1から6分の1の性能だが、GPUアクセラレーターで構成されたシステムの将来性を示している。HPEはRadix 64の12.4Tスイッチを用いたHigh Radix Networkを特長としている(ただし3段構成)。Radixが128、256、512と大きくなると、さらなる性能向上が期待できる。
これらの例から、以下の3つの接続を考える必要があることが分かる。
- ノード間接続
- ノードとローカルメモリ(不揮発メモリ、SCM:(Storage Class Memory)やメインメモリ)間接続
- ローカルメモリとメインストレージ間接続
図8は、よく引用されるCPOの適用システムである。この図はCOBO PresidentのBrad Booth氏が講演した2021年12月のLightwave Webcastの配布資料から引用した。上記の3つの接続ネットワークへの適用を示している。

現在はNVIDIA A100などにあるようにPCIe 4.0が主流だが、図8ではPCIe 6.0を想定しておりさらなる広帯域化が要求される。また、PCIe 6.0を使用したIntel主導のCXL 3.0も想定されていて、GPU(xPU)とローカルメモリとの直接アクセスも高速化されるはずだ。
富岳のノード数は16K、Google TPU v4は4Kである。将来、32K、64K、128Kと増加したときにも耐えられるアーキテクチャを想定し、High Radix Networkによる高速大容量、低レイテンシの接続を実現する光トランシーバーの開発に拍車が掛かっている。
期待に応えられるデバイスだけでなく、小型、高集積実装を実現するForm Factorの規格化が続くと期待したい。
筆者プロフィール
高井 厚志(たかい あつし)
30年以上にわたり、さまざまな光伝送デバイス・モジュールの研究開発などに携わる。光通信分野において、研究、設計、開発、製造、マーケティング、事業戦略に従事した他、事業部長やCTO(最高技術責任者)にも就任。多くの経験とスキルを積み重ねてきた。
日立製作所から米Opnext(オプネクスト)に異動。さらに、Opnextと米Oclaro(オクラロ)の買収合併により、Oclaroに移る。Opnext/Oclaro時代はシリコンバレーに駐在し、エキサイティングな毎日を楽しんだ。
さらに、その時々の日米欧中の先端企業と協働および共創で、新製品の開発や新市場の開拓を行ってきた。関連分野のさまざまな学会や標準化にも幅広く貢献。現在はコンサルタントとして活動中である。
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
 光トランシーバーのForm Factorの新動向(3) 〜FacebookやMicrosoftが主導するCPO
光トランシーバーのForm Factorの新動向(3) 〜FacebookやMicrosoftが主導するCPO
2000年以降データセンターを支えてきたSFP、QSFPなどのFront Panel Pluggable光トランシーバーから根本的に変革し、次世代の主流になるかもしれないCPOを解説する。 「光トランシーバー」は光伝送技術の凝縮
「光トランシーバー」は光伝送技術の凝縮
今回から、光トランシーバーについて解説する。データセンター、コンピュータや工場内ネットワークで使用される80km程度以下の中短距離光リンクを中心に、ストレージ、ワイヤレスやアクセス通信ネットワークなど、多様なアプリケーションで使用されている光トランシーバーを紹介する。 光ファイバーとシリコン光導波路を結合する技術
光ファイバーとシリコン光導波路を結合する技術
今回は、光ファイバーとシリコン光導波路を結合する技術を解説する。 100Gbpsを超える光ファイバー高速伝送へのアプローチ
100Gbpsを超える光ファイバー高速伝送へのアプローチ
今回は、100Gビット/秒(bps)と極めて高速な変調信号を光ファイバーで伝送する実験結果を紹介する。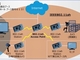 「802.11ah(Wi-Fi HaLow)」の実証実験を公開
「802.11ah(Wi-Fi HaLow)」の実証実験を公開
802.11ah推進協議会は、IoT(モノのインターネット)通信システムに向けたWi-Fi規格「IEEE 802.11ah(Wi-Fi HaLow)」について、総務省から「実験試験局免許」を取得した。「ワイヤレスジャパン2019」でその実証実験を公開する。 データセンターを支える光伝送技術 〜ハイパースケールデータセンター編
データセンターを支える光伝送技術 〜ハイパースケールデータセンター編
今回は、エンタープライズデータセンターに続き、GoogleやFacebook、Appleなどが抱える巨大なデータセンター、「ハイパースケールデータセンター」について解説する。