メモリ消費量を94%削減、富士通の生成AI再構築技術:AIの軽量化と省電力が可能に
富士通は、AIの軽量化や省電力を可能にする「生成AI再構成技術」を開発、同社大規模言語モデル(LLM)「Takane」に適用し、その能力を強化した。従来に比べメモリ消費量を最大94%削減でき精度維持率は89%を達成、推論速度は3倍となった。ローエンドのGPUを用い、エッジデバイス上でAIエージェントの実行が可能となる。
「量子化技術」と「特化型AI蒸留技術」のコア技術で構成
富士通は2025年9月、AIの軽量化や省電力を可能にする「生成AI再構成技術」を開発、同社大規模言語モデル(LLM)「Takane」に適用し、その能力を強化したと発表した。Takaneに搭載した量子化技術により、従来に比べメモリ消費量を最大94%削減でき精度維持率は89%を達成、推論速度は3倍となった。ローエンドのGPUを用い、エッジデバイス上でAIエージェントの実行が可能となる。
AIエージェントが実行するタスクのほとんどは、LLMが持つ汎用的な能力の一部しか必要としないという。今回開発した生成AI再構成技術は、巨大なモデルの中から特定業務に必要な知識だけを取り出し、特化したAIモデルを作り出すことによって、軽量化や省電力化を実現した。
生成AI再構成技術は2つのコア技術から成る。その1つは、AIの施行を効率化し消費電力を削減する「量子化技術」である。膨大なパラメーターの情報を圧縮することで、生成AIモデルの軽量化や省電力化、高速化を実現した。具体的には、層をまたいで量子化誤差を広く伝わらせることで増大を防ぐ「量子化アルゴリズム(QEP)」を新たに開発。さらに、大規模問題向けの最適化アルゴリズム「QQA」を活用し、LLMの1ビット量子化を実現した。
![量子化技術の概要[クリックで拡大] 出所:富士通](https://image.itmedia.co.jp/l/im/ee/articles/2509/10/l_tm_250910fujitsu01.jpg)
もう1つのコア技術は、専門知識を凝縮し精度を向上させる「特化型AI蒸留技術」である。基盤となるAIモデルに対して、不要な知識をそぎ落とす「Pruning(枝刈り)」や、新たな能力を付与する「Transformer」ブロックを追加し、さまざまな構造のモデル候補群を生成する。
その上で、これら候補の中から顧客の要望と精度のバランスを考慮しながら、最適なモデルを自動で選定する。最後に、選定されたモデルに対し、Takaneなどの教師モデルから必要な知識だけを取り出す。こうした方法を採用することで、単なる圧縮にとどまらず、特化したタスクでは、基盤の生成AIモデルを上回る精度を実現できたという。
富士通はこうして得られたモデルを用い、自社のCRMデータでその能力を検証した。この結果、推論速度が11倍となり精度は43%も改善できた。つまりパラメーターサイズが100分の1という軽量な生徒モデルで、教師モデルを上回る精度が得られたことになる。AI処理に必要なGPUメモリと運用コストもそれぞれ70%削減できるという。
これとは別の画像認識タスクについても検証した。未学習の物体に対する検出精度は、既存技術と比べ10%も向上させることができた。
![特化型AI蒸留技術の概要[クリックで拡大] 出所:富士通](https://image.itmedia.co.jp/l/im/ee/articles/2509/10/l_tm_250910fujitsu02.jpg)
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
 「富岳NEXT」開発が始動 GPUでNVIDIA参画、Rapidus採用の可能性も
「富岳NEXT」開発が始動 GPUでNVIDIA参画、Rapidus採用の可能性も
理化学研究所(以下、理研)は、スーパーコンピュータ「富岳」の次世代となる新たなフラグシップシステム(開発コードネーム「富岳NEXT」)の開発体制が始動したと発表した。全体システムやCPUの基本設計は富岳から続けて富士通が担うほか、今回初めてGPUを採用し、その設計にNVIDIAが参画する。 富岳を継承 富士通次世代プロセッサ「MONAKA」の詳細を聞く
富岳を継承 富士通次世代プロセッサ「MONAKA」の詳細を聞く
富士通は、次世代データセンター向けの省電力プロセッサ「FUJITSU-MONAKA」の開発に取り組んでいる。その特徴やターゲットアプリケーションについて、富士通 富士通研究所 先端技術開発本部 エグゼクティブディレクターの吉田利雄氏に聞いた。 富士通「MONAKA」×AMD GPUで目指す「AIのオープン化」
富士通「MONAKA」×AMD GPUで目指す「AIのオープン化」
富士通とAMDは2024年11月、電力性能に優れた最先端プロセッサと柔軟性の高いAI(人工知能)/HPC(高性能コンピューティング)ソフトウェア群からなるAI/HPCコンピューティング基盤の実現に向けて、技術開発から事業までの戦略的協業に関する覚書(MOU)を締結した。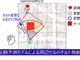 AI技術でつながりやすいモバイルネットワーク実現
AI技術でつながりやすいモバイルネットワーク実現
富士通は、人工知能(AI)技術を活用し、モバイルネットワークの通信品質向上や省電力化を可能にしつつ、有事の際なども「つながりやすさ」を実現するアプリケーションを開発した。 富士通とSupermicro、AIシステム基盤の開発で協業
富士通とSupermicro、AIシステム基盤の開発で協業
富士通とSuper Micro Computerは、戦略的協業を始める。電力消費を抑えた高性能プロセッサ技術や環境に配慮した水冷技術などを持ち寄り、次世代プロセッサ「FUJITSU-MONAKA」を搭載したデータセンター向け「AIコンピューティングプラットフォーム」を、2027年より提供していく予定である。 富士通セミコンダクターメモリソリューション、「RAMXEED」に社名変更へ
富士通セミコンダクターメモリソリューション、「RAMXEED」に社名変更へ
富士通セミコンダクターメモリソリューションは、2025年1月1日付で「RAMXEED」に社名を変更すると発表した。