東工大ら、PIM型NNアクセラレーターのマクロを開発:モバイルエッジ機器向けAI技術
東京工業大学と工学院は、モバイルエッジデバイスに搭載可能な、PIM(プロセッシングインメモリ)型ニューラルネットワーク(NN)アクセラレーターのマクロを開発した。動作時と待機時の電力消費が極めて小さく、高い演算能力とエネルギー効率を実現できるという。
動作時で99%、待機時で84%もの電力消費を削減
東京工業大学科学技術創成研究院未来産業技術研究所の菅原聡准教授と工学院電気電子系の塩津勇作博士後期課程大学院生(研究当時)らによる研究グループは2023年4月、モバイルエッジデバイスに搭載可能な、PIM(プロセッシングインメモリ)型ニューラルネットワーク(NN)アクセラレーターのマクロを開発したと発表した。動作時と待機時の電力消費が極めて小さく、高い演算能力とエネルギー効率を実現できるという。モバイルエッジデバイスに搭載可能なAI技術として注目される。
SRAM技術を用いたPIM型NNアクセラレーターは、高い性能を得ることができ、現行のCMOS技術で実装することが可能である。また、エネルギー効率を向上させるには、エネルギー最小点(EMP)となる駆動電圧(VEMP)を用いた推論動作が効果的だという。これによって、積和(MAC)演算の並列数を増やすことも可能になる。
研究グループは最近、3モード動作を実現した超低電圧リテンションSRAM(ULVR-SRAM)セルを提案した。モードの1つ目は通常電圧(VDD=1.2V)下で、従来SRAMと同等の性能で動作する。2つ目は0.2V程度の超低電圧(VUL)になっても、データを保持(ULVR)できるため、待機時の消費電力を大幅に削減できる。3つ目はEMPとなる電圧(VEMP=0.4V)での動作も実現できる可能性があり、エネルギー効率を最大化できる、という3つである。
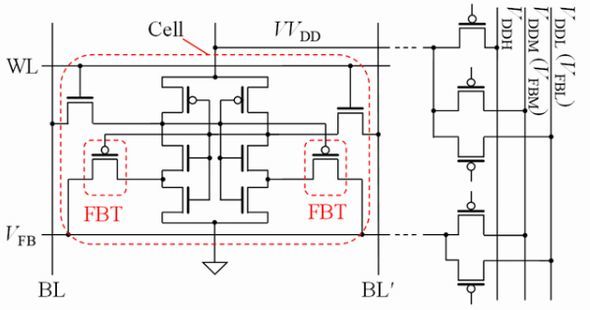
今回はまず、トランジスタの特性バラツキを考慮しつつ、3モード動作を実現できるULVR-SRAMセルの設計技術を開発した。その上で、ULVR-SRAMセルを用いPIM型NNアクセラレーターのマクロを設計した。NNアーキテクチャには2値化ニューラルネットワーク(BNN)を用いた。
開発したPIM型BNNアクセラレーター(BNA)マクロは、1個のマクロで256ビットの入力ベクトルに対する積和演算が可能だという。BNAマクロには、重みデータとバイアスデータを格納するためのULVR-SRAMが用意されている。これらを同時に読み出すことで、効率的にMAC演算を実行し、アクティベーション判定を行う。
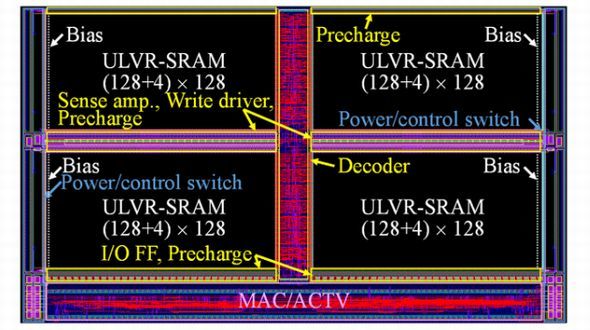
開発したBNAマクロのPG(パワーゲーティング)性能を調べ、待機電力削減効果を評価した。メモリセル部をVUL=0.2Vでデータ保持し、その他の回路は電源を遮断した。この結果、クロックゲーティング時のスタンバイ状態に比べ、待機時の電力を84%削減できることが分かった。6TセルのSRAMを用いた場合に比べると、94%の削減になるという。
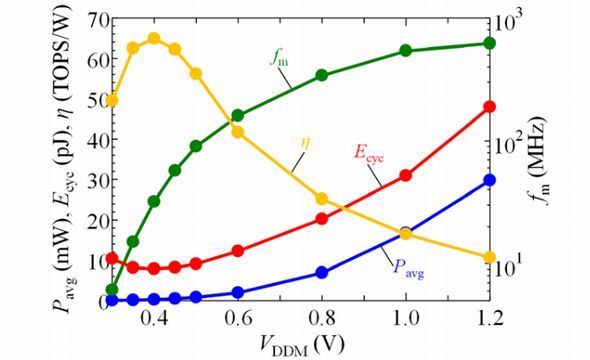
続いて、推論動作時の性能を評価した。電源電圧(VDDM)が小さくなると、平均動作時電力(Pavg)と動作周波数(fm)は減少し、0.4Vで消費エネルギー(Ecyc)が最小になった。つまり、0.4VがVEMPとなり、この作動点では通常電圧動作(1.2V)に比べ、動作周波数(fm)は1/10となり、動作時電力は1/100(99%減)となる。これは、MAC演算の並列化に極めて有効だという。BNAにおける推論のエネルギー効率(η)は、0.4Vで最大となり65TOPS/Wと極めて高い値となった。
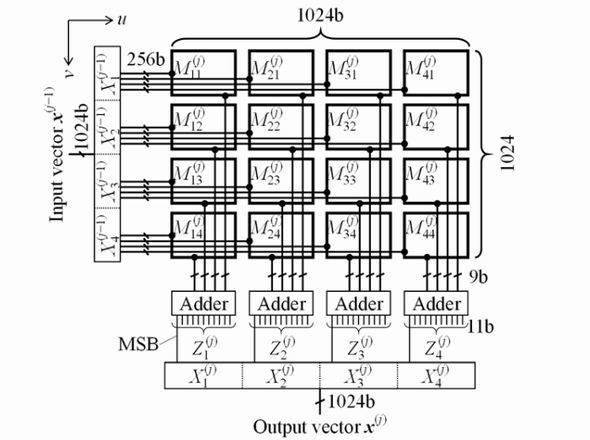
開発した複数のBNAマクロを用い、1024ノードの全結合層を構成した。Muv(j)が1つのBNAマクロである。v軸(縦)方向にある複数のBNAマクロを同時にMAC演算することをノード内並列化(INP)、u軸(横)方向にある複数のBNAマクロを同時にMAC演算することをレイヤー内並列化(ILP)と呼ぶ。それぞれの並列数を「NINP」「NILP」とすれば、全体の並列数(NP)は、NINPとNILPで表すことができる。1マクロ当たりMAC演算ユニットを1つ有する場合、NPは16となる。1マクロ当たりMAC演算ユニットを増設すれば、NPを大きくすることができる。
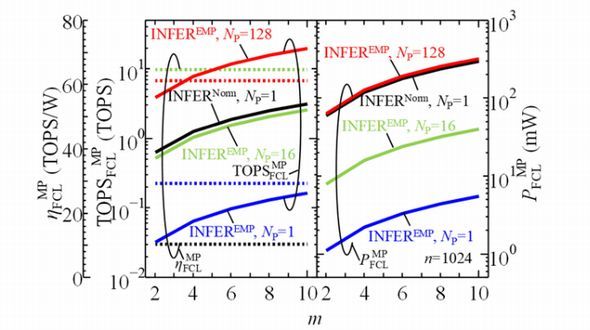
研究グループは、並列化の効果についても検証した。平均動作時電力(PFCLMP)や演算能力(TOPSFCLMP)および、エネルギー効率(ηFCLMP)について、ネットワーク層数(m)との関係性を調べた。全結合層1層当たりのニューロン数は1024である。
検証した結果、「MAC演算の並列化によって高性能化を実現できる」「NP=16の場合に、EMP動作によって1.2V動作時と同程度の演算性能を保ちながら、Pavgを1.2V動作時の約1/10にできる」「NPを128にすると、Pavgは1.2V動作時と同程度でありながら、演算量を約10倍に増大できる」「EMP動作時の演算効率は、どの場合でも約65TOPS/Wと極めて高い」ことなどが分かった。
研究グループは、「今回開発した成果を、たたみ込み層に応用すれば200TOPS/W以上の高いエネルギー効率を得ることができる」という。
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
 最高の酸化物イオン伝導度を示す酸塩化物を発見
最高の酸化物イオン伝導度を示す酸塩化物を発見
東京工業大学は、200℃以下の低温域で酸化物イオン伝導度が最高値となる、新たな「酸塩化物」を発見した。その結晶構造とイオン拡散経路、酸化物イオン伝導度のメカニズムも解明した。 水素を活用、酸化物熱電材料の熱電変換効率を向上
水素を活用、酸化物熱電材料の熱電変換効率を向上
東京工業大学は、チタン酸ストロンチウムの多結晶体に水素を取り込むことで、「低い熱伝導率」と「高い電気出力」を同時に実現し、熱電変換効率を高めることに成功した。 巨大なスピン振動による非線形の応答を観測
巨大なスピン振動による非線形の応答を観測
京都大学と東京大学、千葉大学、東京工業大学らの研究グループは、らせん状の金属メタマテリアル構造を反強磁性体「HoFeO3」に作製し、その内部に最大約2テスラのテラヘルツ磁場を発生させ、巨大なスピン振動による非線形の応答を観測した。 耐放射線Ka帯フェーズドアレイ無線機を開発
耐放射線Ka帯フェーズドアレイ無線機を開発
アクセルスペースと東京工業大学は、低軌道通信衛星コンステレーションに向けて「放射線耐性の高いKa帯無線機」を開発した。「Beyond 5G」に向けて、小型衛星の通信速度を大幅に向上させられる技術だという。 β型酸化ガリウムにおける水素の準安定状態を解明
β型酸化ガリウムにおける水素の準安定状態を解明
茨城大学や東北大学、東京工業大学らの研究グループは、次世代パワー半導体材料であるβ型酸化ガリウム(β-Ga2O3)の電気特性に影響を与える水素の準安定状態を解明した。 東工大、マルチバンドフェーズドアレイ受信IC開発
東工大、マルチバンドフェーズドアレイ受信IC開発
東京工業大学は、Beyond 5G端末機に向けた「マルチバンドフェーズドアレイ受信IC」を開発した。新たに提案した高周波選択技術を採用したことで、24G〜71GHzというミリ波帯の全バンドに、1チップで対応することができるという。