「PCIe 6.2+CXL 3.1」でAI性能向上の限界を超える:インターコネクト技術が鍵に(1/2 ページ)
既存のAI技術を発展させるには、演算能力のみならず、データ転送、メモリ使用量など、さまざまな要素の限界を乗り越える必要がある。そうした解の一つがインターコネクト技術の発展だ。
既存のAI技術で、映画に出てくるようなAIを全て実現できるようになるには、計算需要や、膨大なデータ転送、リアルタイム処理、メモリ使用量などの限界を打ち破らなければならない。既存のコンピューティングアーキテクチャは、PCI Express(PCle)インターコネクトだけに依存しており、AIワークロードの急激な進化に後れを取らずに付いていくのは難しい。そこに、CXL(Compute Express Link)規格の最新世代であるCXL 3.1が登場し、メモリ/リソース割り当ての新たな手法を提供している。
CXL対応のメモリプーリング:AIの新たなパラダイム
米国半導体工業会(SIA:Semiconductor Industry Association)の調査によると、既存のAIワークロードの性能非効率性のうち、全体の最大40%をメモリボトルネックが占めていることが明らかになったという。CXLは現在、複数の処理装置でアクセス可能な共有メモリプールを実現することにより、この問題を軽減することを目指している。
CXL 3.1(リリース自体は2023年11月)は、単に帯域幅を増やすのではなく、メモリのアクセス/共有方法を再定義する。CXLが、CPUやGPU、アクセラレーター全体でダイナミックなメモリプーリングを実現することで、AIシステムはより効率的にリソースを最適化できるようになる。こうしたアプローチには、以下のような重要なメリットがある。
- メモリボトルネックの解消:AIモデルは膨大なメモリリソースを必要とするため、既存アーキテクチャの非効率性につながる場合が多い。CXL 3.1は、共有メモリモデルを採用し、レイテンシの低減や利用率の最大化を実現できる
- 消費電力量の低減:CXLは、AIワークロードを必要なメモリの割り当てに集中させることで、不必要な電力使用を最小限に抑え、よりエネルギー効率の高いAIトレーニング/推論を実現する
- AIアプリケーションのシームレスなスケーリング:AI開発者はフレキシブルなメモリ共有アーキテクチャを採用することで、CPU/GPU/DPUに見られる既存のメモリ階層の限界に制限されることなく、より複雑なモデルを構築できるようになる
AIアクセラレーションの“ハイブリッド手法”
CXLはメモリ管理に革命を起こしたが、PCIeは今もまだ高速データ転送に不可欠な存在だ。PCIe 5.0は、最大128GB/秒の双方向帯域幅を提供し、AIアプリケーション向けに高速データのクロスオーバーを確保する。このようなデータ転送速度は、ハイブリッド手法が威力を発揮するPCIe 6.2のイノベーションにより、さらに高まっていくと期待されている。
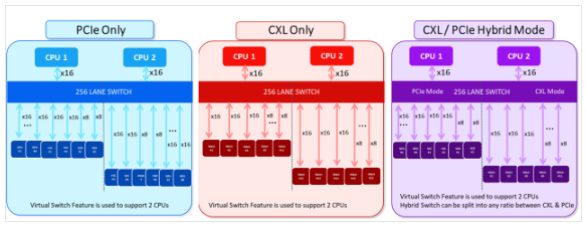 CXLとPCIeの“ハイブリッド活用”のイメージ
CXLとPCIeの“ハイブリッド活用”のイメージPCIe 6.2とCXL 3.1を統合ソリューションで活用することにより、両規格の強みを柔軟に生かせる。こうしたハイブリッド手法は、高速データ移動や、効率的なメモリ共有、将来も有効なインフラなどを実現できるため、特に複雑なAIシステムにとってメリットがある。
PCIe 6.2は、超高速データ転送速度を提供し、AIアクセラレーターが必要なデータを遅延なく確実に受信できるようにする。CXL 3.1は、複数の処理装置が共有メモリプールに動的にアクセスできるようにすることで、メモリ利用率を高められる。1つのSoC(System on Chip)上でPCIe 6.2とCXL 3.1をサポート可能なハイブリッドスイッチは、次世代AIワークロード向けにシームレスなアップグレードとスケーラビリティを実現する。
Copyright © ITmedia, Inc. All Rights Reserved.
記事ランキング
- メモリ市場が大爆発 「5年の壁」を乗り越えられるか
- マイクロン、AI需要で広島工場増強へ起工式 1.5兆円投資
- 米国でInnoscience製GaN販売禁止 Infineonへの特許侵害が確定
- キオクシア、第10世代「BiCS FLASH」を北上で生産開始 AI需要に照準
- メモリ価格の上昇、鈍化へ 26年3QはDRAMもNANDも10%台
- メモリ起点に後工程へ本格参入 半導体の総合材料メーカー目指すADEKA
- パワー半導体企業ランキング、日本勢は三菱電機ら5社がトップ20入り
- ぼっち系エンジニア、「幸せ」について論文とデータで殴られる
- 世界半導体市場、26年5月は1206億ドル 日本も前年比23%増
- ルネサスが描く2035年 「AIがユーザーになる時代」の成長戦略
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。