ArmのAI戦略、見え始めたシナリオ:IPベンダーならではの出方(2/4 ページ)
NEONの拡張
さて話を戻すと、先にこのインフラを整えたことで、アクセラレータ類を搭載する下地ができたことになる。その上でまずCortex-A55/A75に、Int 8のdot Productの演算機能を追加した。「ARMの新型コア「Cortex-A75/A55」、AIを促進」には詳細が書かれていないが、これはARM v8.2a(命令セット)におけるSIMDエンジンであるNEONの拡張である。dot product、日本語だとドット積などというが、
A・B=A1B1+A2B2+……AnBn
というベクトル演算の一種である。
これが役に立つのは、MLの中でもCNN(Convolutional Neural Network)の処理で、このdot productの演算を煩雑に行うからである。Convolution(畳み込み)という計算がまさにこのdot productの演算そのもので、従ってこれを利用することでよりCNNが高速に動作できるようになった。
問題はこの性能がどれほどか、である。このNEONの拡張により、1cycle当たり16のdot product演算が可能になった。Cortex-A55/A75はこのNEONユニットをコア当たり2つ搭載するので、演算性能は32 OPs/cycleとなる。数字の検証は後でご紹介するが、この数字は必ずしもそれほど高いとは言えない。とはいえ、通常のFPUでやるよりも高効率なのは事実で、それほど複雑でないCNNの推論程度には使える、というレベルである。
Project Trilliumを発表
これに続き、2018年2月に同社は「Project Trillium」を発表した(参考リリース。日本語版はこちら)。Project Trilliumはまだプロジェクトコード名の段階で、実際の製品名/ブランド名ではない、とされている。骨子はこちらにまとめられているが、
- CNNの汎用プロセッサと思われる「Arm ML Processor」(図4)、それと画像分析系の「Arm OD Processor」の2つが提供される
- Arm ML Processorは「Fixed-function Engine」と「Programmable Layer Engine」から構成され、これを複数個搭載できる。ちなみに両者の違いだが、説明ではこのProgrammable Layer Engineについて"for furure-proofing"という言い方をしているあたり、現状見えている範囲でのCNN向けフレームワークのほとんどは、Fixed-function Engineでほぼ処理可能と思われる
- Arm ML Processorに関する数字としては3TOPs/W、それと最大で4.6TOPs/secという数字が示されている。またフレームワークとしてArmNN(Arm Neural Network)SDKと、幾つかの主要なフレームワーク(TensorFlowやCaffeなど)が提供される
- Arm OD ProcessorはFull HDまでの画像に対して、50×60ピクセル〜全画面までのサイズの対象物をリアルタイム(60fps)で検出する。同社によれば、従来*)のDSP比で80倍の性能が実現されるとする
といったものである。
*)『従来』が何に相当するのか不明だが、Cortex-M4のDSP演算あたりを基準にしているのではないかと思われる。こちらにもあるが、Arm NNにははCortex-Mプロセッサをターゲットにした「CMSIS-NN」というフレームワークが含まれており、これを比較基準にしても不思議ではないからだ。
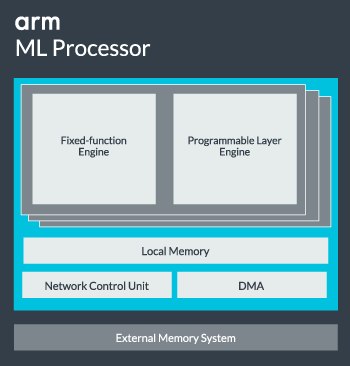 図4:ML Processorの概略図。内部にもある程度Local Memoryを持つことで、Poolingなどの処理での外部メモリアクセスの必要性を減じることで、性能改善と消費電力削減を両立するとしている 出典:Arm
図4:ML Processorの概略図。内部にもある程度Local Memoryを持つことで、Poolingなどの処理での外部メモリアクセスの必要性を減じることで、性能改善と消費電力削減を両立するとしている 出典:Arm2018年の「MWC(Mobile World Congress)」においては、Arm OD Processorに関しては実働デモも行われている。ちなみにArm ML ProcessorもArm OD Processorもターゲットはモバイル機器のようであり、MWCではこんなデモも行われていた(参考動画:30秒付近から。撮影した画像から車種の認識を行っている)。
なお、どちらのProcessor IPも2018年4月からEarly Previewが提供され、一般提供開始は同年中ごろ(つまり5〜8月あたり)を予定しているというのが現在の状況である。
このうち、特にML Processorに関しては、今のところ詳細を明らかにする予定は無い(いつ詳細を明らかにするかも決めていない、との事だった)そうで、まだ詳細は闇の中である。
Copyright © ITmedia, Inc. All Rights Reserved.
記事ランキング
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。