損保ジャパン日本興亜と理研、安全運転を支援:自動車走行データをAIで解析
損害保険ジャパン日本興亜と理化学研究所革新知能統合研究センターは、機械学習技術を活用して自動車走行データを解析する技術を開発した。
交通事故ゼロへ高度なサービスを提供
損害保険ジャパン日本興亜(損保ジャパン日本興和)と理化学研究所(理研)革新知能統合研究センター(AIPセンター)は2019年11月、機械学習技術を活用して自動車走行データを解析する技術を開発したと発表した。損保ジャパン日本興亜は、解析で得られたデータを基に、交通事故削減に向けた高度なサービスを運転者に提供していく。
損保ジャパン日本興亜はこれまで、顧客が所有するスマートフォンやドライブレコーダーから得られる膨大な自動車走行データを活用した、いくつかの「安全運転支援サービス」を提供してきた。「スマイリングロード」や「ポータブルスマイリングロード」「DRIVING!(ドライビング!)」と呼ぶサービスである。
こうした中、機械学習技術に関して同社は、理研AIPセンターと2018年3月より共同研究を行ってきた。今回発表した「運転データによる大規模ドライバー識別技術」と「多重比較補正を利用した統計的軌跡マイニング技術」は、共同研究の成果である。
「運転データによる大規模ドライバー識別技術」は、スマートフォン用カーナビアプリ「ポータブルスマイリングロード」で収集した運転データを用い、数千人規模の運転手を対象とした大規模識別問題を機械学習で解析した。
これによって、1台の車両を複数の運転手が共有して運行している場合でも、当該運転手を識別して運転データを分類し、運転手ごとの運転診断を行うことができるという。最大1万人を対象として実施した識別実験でも、高い精度で運転手を識別できることが分かった。

「多重比較補正を利用した統計的軌跡マイニング技術」では、「Stat-DSM(Statistically Discriminative Sub-trajectory Mining)」と呼ばれる手法で、「Trajectory Mining」における統計的信頼度を評価した。
属性が異なるグループ(例えば、事故歴のあるドライバーと無事故のドライバー)の移動軌跡パターンがあれば、その差異を調べる。特徴的な軌跡パターンを検出する場合、観測データに含まれる誤差を軽減するため、統計的な評価をしながら軌跡パターンの抽出を行う必要があるという。Stat-DSMは、木のような形状をしたデータ構造に軌跡パターンを格納し、統計的推論を行うことで、大規模なデータの計算を可能にした。
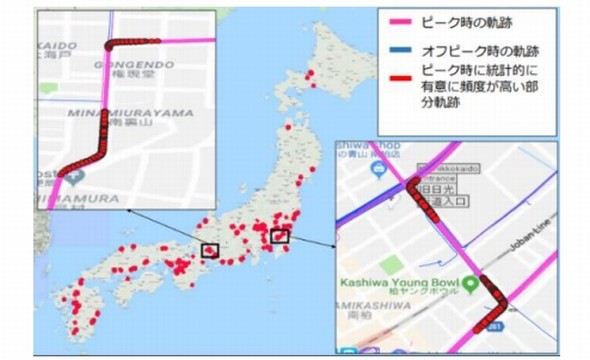 異なるグループ間における軌跡パターンの差異 出典:損保ジャパン日本興亜、理研
異なるグループ間における軌跡パターンの差異 出典:損保ジャパン日本興亜、理研関連記事
 理研ら、有機トランジスターで超伝導状態を制御
理研ら、有機トランジスターで超伝導状態を制御
理化学研究所(理研)らの共同研究グループは、有機物の強相関物質を用いた電気二重層トランジスターを作製し、電子の「数」と「動きやすさ」を同時に変化させることで、超伝導状態を制御することに成功した。 理研、室温付近で「電場による磁化制御」に成功
理研、室温付近で「電場による磁化制御」に成功
理化学研究所(理研)は、マルチフェロイック物質である「六方晶鉄酸化物」の単結晶試料を合成し、室温付近で「電場による磁化制御」に成功した。 理研ら、微小な磁気渦を形成する磁性材料を開発
理研ら、微小な磁気渦を形成する磁性材料を開発
理化学研究所(理研)らによる研究グループは、微小な磁気渦(磁気スキルミオン)を形成する新たな磁性材料の開発に成功した。 VolkswagenとFordが自動運転開発で提携拡大へ
VolkswagenとFordが自動運転開発で提携拡大へ
Volkswagenは2019年7月、Ford Motor(以下、Ford)の自動運転部門であるArgo AIに31億米ドルを投資することで合意した。Argo AIは米国ペンシルベニア州ピッツバーグを拠点とする新興企業で、自動運転車(AV)向けのフルスタックプラットフォームの開発に注力している。 AI戦略、NXPの立ち位置とは
AI戦略、NXPの立ち位置とは
NXP Semiconductorsにおける、機械学習分野の開発は現在、どのようになっているのか。同社のAI戦略・パートナーシップ部門担当ディレクターを務めるAli Osman Ors氏に聞いた。 ニューラルネットだって混乱する!その対策は?
ニューラルネットだって混乱する!その対策は?
安全な自律性を実現すること」は、AIベースの自動運転車の開発者にとって、解決することが最も難しい問題の1つとして挙げられる。米国ペンシルベニア州ピッツバーグに拠点を置く新興企業Edge Case Researchは、認識スタック のエッジケース(境目ぎりぎりで起こる特殊なケース)を識別する安全性評価プラットフォーム「Hologram」を開発している。
Copyright © ITmedia, Inc. All Rights Reserved.
記事ランキング
- ソニーが新画素構造「RB2×2 OCL」採用センサー 高解像度とAF性能を両立
- TSMC撤退の逆風越え、浜松に技術者集結――27年GaN内製化へ全力のローム
- AIが食い尽くすメモリ供給 企業ITを揺らす価格高騰
- 次世代チップ積層に関する3つの基盤技術を開発
- AmazonはNVIDIAに挑戦状を突きつけるのか
- 世界半導体市場が初の単月1000億ドル超え、26年4月
- 車載は「新たな成長段階に」 SiCパワー半導体市場、5年後110億ドル規模へ
- 宙に浮く透明な会議室? 村田製作所の新拠点から見る「オフィスの現在形」
- パッケージ基板の配線微細化と歩留まりを両立させる新製法
- 反りも割れも抑制 先端パッケージ向け多層セラミックコア基板
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。