モノマネする人工知能 〜 自動翻訳を支える影の立役者:Over the AI ―― AIの向こう側に(16)(7/10 ページ)
AIの翻訳と、私たちの英語学習法を比べてみる
さて、ここで自動翻訳の技術の内容を、私たちがこれまで受けてきた(or 受けている)英語の勉強法と比較してお話しします。

このように対比してみると明らかなのですが、自動翻訳技術の4つの方法は、私たちがやってきた英語の勉強の方法と、ほとんど変わりがありません。
加えて言えば、かつての自動翻訳技術も、日本の英語教育も、その方式で「スタック(停滞)」してしまっている点も同じです(もちろん、何もしないよりはずっとマシなのですが)。
以前担当させて頂いた「技術英語」に関する連載「「英語に愛されないエンジニア」のための新行動論」で、私は「最小限の例文だけを暗記しろ*1)」「訳が分からなくてもいいから英語を読みまくれ*2)」「デタラメでもいいから英語を書きまくれ*3)」と言い続けてきたのですが、最近の自動翻訳技術(EBMT、SMT)パラダイムから見ても、これらは、そこそこ正解だったのではないかと思っています。
*1)「―実践編(パラダイムシフト)―入出力装置という「機械的な私」の作り方」
*2)「仮説検証方式」で調査時間を1/10に短縮しよう
*3)“Japanese English”という発想(前編)
次に、用例ベース機械翻訳(EBMT)技術と、統計的機械翻訳(SMT)技術の両方をざっくりとまとめて、暗号解読のアプローチと比較してみました。

翻訳とは暗号解読である ―― この割り切りさえできれば、翻訳とは単なる、情報理論(確率論を含む)に元づく信号処理/情報処理として取り扱うことができます。
"「言語」とは、「人間相互理解」の道具であり、「民族」という単位のポピュラーな指標であり、「文化」という荷物を過去から未来へ運ぶリヤカーのような役割"*)―― てな、高尚なことは、いったん全て忘れてしまい、「言語」を単なる信号変換処理の対象として、淡々と無機質に取り扱うだけで ―― 皮肉なことに ―― 優れた翻訳ができてしまう、ということです。
*)関連記事:「―実践編(パラダイムシフト)――技術英語はプログラミング言語である」
さて、話を戻しまして、上図で記載されている「対訳コーパス」と、それを使った翻訳の概念図を以下に示します。
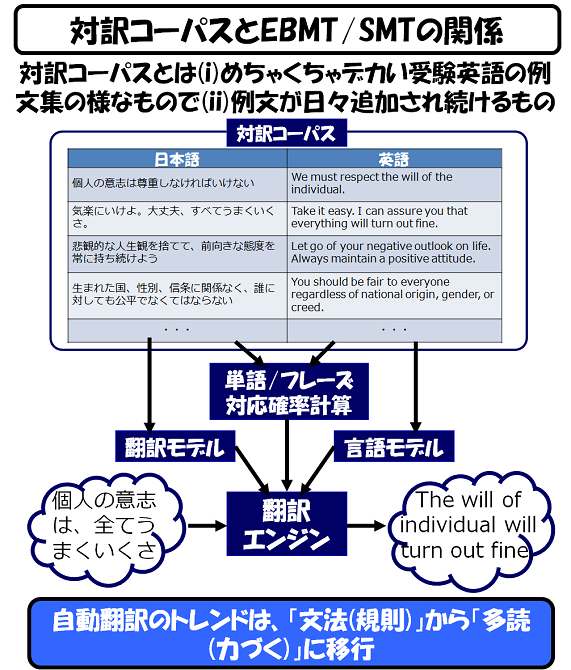
要するに、現在の自動翻訳技術の主流は、膨大な例文と、膨大な速度の確率計算で、力づくで翻訳結果を導き出すもの、と、ご理解いただければ十分です。
Copyright © ITmedia, Inc. All Rights Reserved.
記事ランキング
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。