至宝の人工知能 〜問題に寄り添い、最適解をそっと教えてくれる:Over the AI ―― AIの向こう側に(17)(2/8 ページ)
先人たちが築き上げた「至宝の最適化アルゴリズム」
こんにちは、江端智一です。今回は、「最適化アルゴリズム」についてお話致します。

また、毎度のことですが、「『最適化アルゴリズム』が"AI技術”なのかどうか」については、今回も『江端AIドクトリン』に基づいて私が ―― と言いたいところなのですが、実は、今回ばかりはどうしても"AI技術"と呼びたくないのです。
―― 先人たちが築き上げてきた「至宝の最適化アルゴリズム」を、軽々しく「AI技術」など呼んで欲しくない
という思い入れが、私にはあるからです。
奥村先生の「C言語による最新アルゴリズム辞典」(奥村晴彦、1991年 技術評論社)は、今なお、私が、オフィス(研究所)の中を20mも歩けば、誰かのデスクの上に1冊は発見できるくらいの名著です。
大学入試で使うような数式の方程式なんぞ使わなくても、「最適なアルゴリズムを使えば、コンピュータの力を使って解が得られる」ということを、魂のレベルで教えてくれた本で、「私のバイブル」といっても過言ではありません(今でも使っています)。
が、まあ、私に"最適化アルゴリズム"に思い入れがあったとしても、このままでは連載を進められないので、"最適化アルゴリズム"を"AI技術"と見なすことにします(不本意ですが)。
第3次AIブームをけん引する「強化学習」や「深層学習」
今回の第3次AIブームにおきましては、強化学習や深層学習が、そのブームをけん引しています。私は、その理由の1つに「神秘性」があると思っています。
私は学生のころ、逆伝搬学習の効率の悪さに(文字通り)『地獄を見た』のですが、深層学習(ディープラーニング)は、この問題を改善して、今やいろいろな分野でニューラルネットワークを使えるようにした、という点において革命的だったと言えます。
また、強化学習は、「結果」だけを使って、そのオペレーション全体を再評価するという方式を使って、「何も教えなくても、放っておけば、勝手に学習していく」というプロセスが、世間の人々の度肝を抜きました。
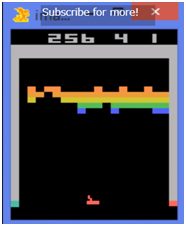
その度肝を抜かせた映像の1つがこちらの「ブロック崩し」のゲーム映像です。
強化学習で、コンピュータに教える知識は、ゲームオーバーになった時の得点のみで、ジョイスティックを「どのように動かせば良いのか」は一切教えません。コンピュータは、「良い得点」を取った時の動かし方が ―― その理由は知らんが ―― とにかく「良い動かし方」と評価された動きを学習するだけです。
これは、「新人の指導を押しつけられた指導員」にとって、夢の具現化と言えます。
なぜなら、強化学習の方法を、新人教育に当てはめれば、「馬鹿野郎!」と「よくやった!」の2フレーズを使うだけで指導ができるわけですから、こんなに楽チンな方法はありません。
しかし、この職人気質(かたぎ)の手法は、現代のエンジニア教育においては、完全に否定されております。あまりにも効率が悪過ぎるからです。
ニューラルネットワークが、解決したい問題に対して適切な構成を込めているかどうかは、運とセンスにかかっており、しかも超高速な計算デバイス(GPUなど)がないと、全く使いものにならない、という特徴があります。
また、ゲームを使った強化学習による学習プロセスの映像では、強化学習が簡単に完了しているかのように見えますが、実際には、膨大な回数のゲームを続けています。仮に数百、数千回ものゲームをやらせ続けたら、1回1分の時間がかかるとして、5000回で83時間、約10営業日かかることになります)。
強化学習とは ―― もし、指導員が新人にゲームの攻略法を教えるというカリキュラム(どんなカリキュラムだ)があったと仮定した時、「ゲームのルールは教えん。ゲームの操作方法も教えん。とにかく、表示される点数を高くする方法を、自分で見つけ出せ」といって、新人に、2週間の時間を与えて、ひたすら5000回ゲームを繰り返しさせる ―― そういう学習方法なのです。
このケースなら、指導員が、たった一言「ボールに追従してバーを動かせ」とだけ指導すれば、このカリキュラムは完了です(所要時間5秒)。
Copyright © ITmedia, Inc. All Rights Reserved.
記事ランキング
- ぼっち系エンジニア、「幸せ」について論文とデータで殴られる
- ルネサスがタイミングデバイス事業売却を完了、売却益4433億円
- カメラでも存在感放つ中国 Insta360/DJIの全天ドローンを分解
- サンケン電気、独自GaN搭載ICを公開 パウデック買収で差別化加速
- ソシオネクスト、TSMC A14活用の高性能コンピュートチップレット開発
- IBMが0.7nm世代の半導体技術発表、5年後実用化目指す
- Infineonがパワー半導体新工場 拠点の能力倍増でAI需要に対応
- 「地球で作れない高性能半導体」宇宙で製造目指す レゾナックら
- 2026年3月期通期 国内半導体装置メーカー 業績まとめ
- 「失敗する機会」を確保 村田製作所のMLCC新R&D拠点
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。