忖度する人工知能 〜権力にすり寄る計算高い“政治家”:Over the AI ―― AIの向こう側に(20)(2/11 ページ)
「忖度」のメカニズムを持った「強化学習」
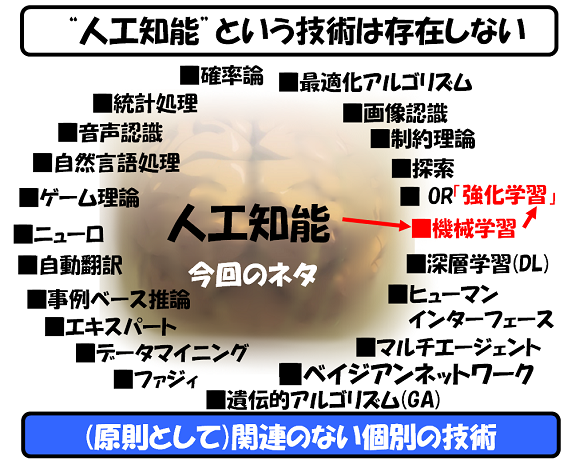
こんにちは、江端智一です。今回は、「機械学習」の中の「強化学習」についてお話したいと思います。
「強化学習」とは、一言で言えば「報酬型学習」、もっと簡単に言えば「褒める学習」です。
しかし、実際に「強化学習」(例えばQ-learning(以下「Q学習」といいます))をコーディングしてみたところ、これは「権力と忖度(そんたく)」のメカニズムを使ったAI技術である、と感じました(後述します)*)。
*)「忖度(そんたく)」とは2018年3月頃に、日本中が大騒ぎになった「森友学園問題」で有名となったパワーワードです(数年後に、このコラムを読んでいる人には、訳の分からない単語になっている可能性がありますので、念のため解説しておきたいと思います)。
この「強化学習」は、いわゆる「教師なし学習」に該当するものですが、この「教師あり学習」と「教師なし学習」を混乱して理解している人が多いようです(そういう私も、良く分かっていませんでした)。
「教師なし学習」という言葉から、「自分で考えて行動する(そして、暴走する)人工知能の学習アルゴリズム」と思っている人が多いようですので、最初にその誤解を解いておきます。

上記で説明したので、詳しくは割愛しますが、要するに、この2つは「学習プロセス」の考え方が違うのです。私なりに、「教師なし学習」を乱暴に纏めると、「勝てば官軍」とか「勝ったのであれば、そこに至る過程は全て正しい」とか、なんというか、体罰を看過する教育現場のようです。
実際に、Q学習をコーディングしてみた私が感じたことは ―― 教師なし学習って、やたら練習を繰り返しさせて、『体で覚えろ』と叫ぶだけの、ロジックで語れない「ぼんくら」 ―― です。
しかし、この結構な「ぼんくら」である「教師なし学習」の「強化学習」と、そして、「教師あり学習」の「深層学習」(次回以降に解説)の2つの学習アルゴリズムこそが、今回の第3次AIブームのきっかけとなり、そしてこのブームを推進しているエンジンそのものであり、そして、第3次AIブームにおいて、私が唯一認めている「2大AI技術」です。
Copyright © ITmedia, Inc. All Rights Reserved.
記事ランキング
- TSMC撤退の逆風越え、浜松に技術者集結――27年GaN内製化へ全力のローム
- ソニーとimec、次世代3D集積向け裏面接続技術を開発
- AIが食い尽くすメモリ供給 企業ITを揺らす価格高騰
- AMDがメモリ最適化技術の新興を買収 「メモリの壁」を打破できるか
- 次世代チップ積層に関する3つの基盤技術を開発
- ソニー初のLOFIC搭載スマホ用画像センサー 飽和電荷量10倍に
- ADI日本法人新代表が語る「追い風」 AI時代にアナログ半導体が担う役割
- 最高速のガラス微細貫通穴加工技術を開発、理研
- 世界半導体市場が初の単月1000億ドル超え、26年4月
- 宙に浮く透明な会議室? 村田製作所の新拠点から見る「オフィスの現在形」
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。