忖度する人工知能 〜権力にすり寄る計算高い“政治家”:Over the AI ―― AIの向こう側に(20)(5/11 ページ)
「強化学習」の有効さ
この単純な報酬型学習である「強化学習」が、どれほど有効であったかは、皆さんもご存じの通りです。

チェスはともかく、絶対に無理だと言われ続けた将棋、囲碁の世界チャンピオンが倒されたことは、記憶に新しいと思います*)。
*)ただし、「Bonanza」「アルファ碁」「AlphaZero」は、単純にQ学習を適用しただけではありません。
コンピュータゲームへの適用は、これより早く始まっていて、積み木くずし、テトリスなども、簡単に攻略されました。
この他、Q学習は、検索問題や枝分かれ問題のような、組合せ爆発系の問題とも親和性が高く、古くから研究が続けられてきた(比較的簡単な)制御装置の自動チューニングにも使えることが分っています。
しかし ―― これだけなのです。
これ以外の事例(例えば、産業応用とか)を、私は見つけ出すことができませんでした。
これは、強化学習だけに限らず、今回の第3次AIブーム全体にいえることです。
AIブームは、社会のツールとして組み込まれた時に、そのブームが終焉(えん)しますので、これは仕方のないことかもしれません(関連記事:「陰湿な人工知能 〜「ハズレ」の中から「マシな奴」を選ぶ」)。
しかし、そうであったとしても、強化学習は私たちAI技術に関わる者の、既存のパラダイムを破壊してしまうほど、すごい技術であることは否めません。
まず、前述したように、その仕組みが驚くほど単純であることは言うまでもないのですが、私たち(特に私)を心底驚かせたのは ―― 「解空間の規模」だったのです。
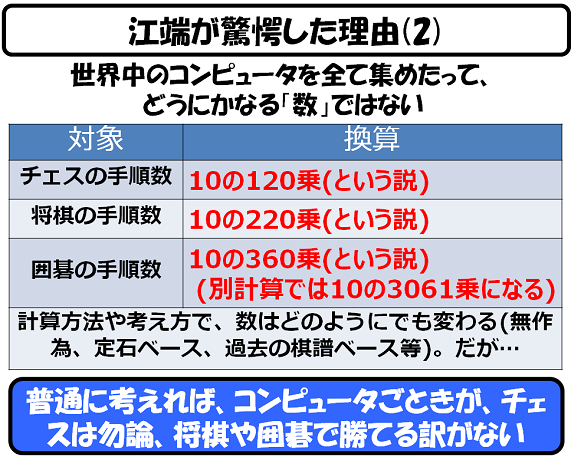
まず、以下の図を、(流し読みせずに)ちゃんと読んでください。

私たちエンジニアが、「大きな数」と言われた時に、イメージする数とはこのくらいのものです。
では、強化学習が相手にした「将棋」や「囲碁」の世界が、どれくらい広いかというと、こんな感じです(流し読みせずに)ちゃんと読んでください(本日2度目)。
Copyright © ITmedia, Inc. All Rights Reserved.
記事ランキング
- TSMC撤退の逆風越え、浜松に技術者集結――27年GaN内製化へ全力のローム
- ソニーとimec、次世代3D集積向け裏面接続技術を開発
- AIが食い尽くすメモリ供給 企業ITを揺らす価格高騰
- AMDがメモリ最適化技術の新興を買収 「メモリの壁」を打破できるか
- 次世代チップ積層に関する3つの基盤技術を開発
- ソニー初のLOFIC搭載スマホ用画像センサー 飽和電荷量10倍に
- ADI日本法人新代表が語る「追い風」 AI時代にアナログ半導体が担う役割
- 世界半導体市場が初の単月1000億ドル超え、26年4月
- 最高速のガラス微細貫通穴加工技術を開発、理研
- 宙に浮く透明な会議室? 村田製作所の新拠点から見る「オフィスの現在形」
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。