忖度する人工知能 〜権力にすり寄る計算高い“政治家”:Over the AI ―― AIの向こう側に(20)(9/11 ページ)
もしも強化学習で“体罰”を与えたら
で、ここまでは予想通りなのですが、実は今回、本当にやってみたかったことは、この強化学習のQ学習で、「体罰」をやってみたらどうなるだろうか、ということでした。
もちろん、Q学習は、「体罰 = マイナスの報酬」を想定して設計されているのではないので、このトライアルは、エンジニア的にはナンセンス(というか、無意味)かもしれません。
しかし、それでも、「褒める(報酬)」ことで効果を発揮するAI技術で、「体罰(マイナスの報酬)」を与えた結果は、冒頭に展開した「体罰の効果」の一つの検証結果になるのではないかと考えました。
ともあれ、やってみました。「J大学に入ると、もれなく1000万円の借金を作る人間になる」 ―― という設定を置いてみたところ、面白い結果が出てきました。
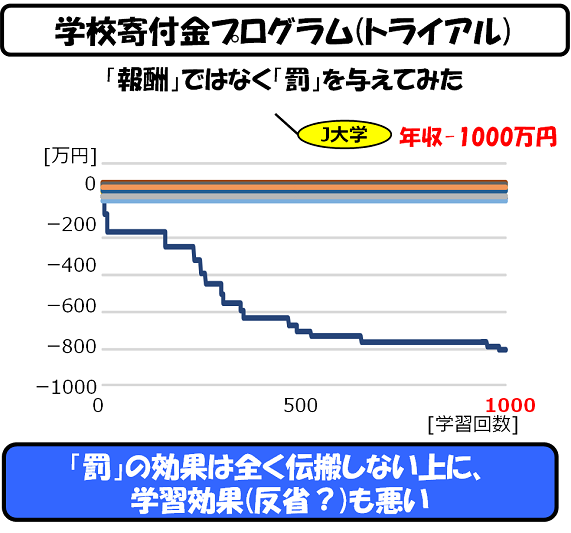
この結果から言えることは、
(1)「(体)罰の効果」は、その事象にのみ限定されて、その効果は全く波及しない。つまり、(体)罰を受けたことのみに効果があり、その問題の原因にさかのぼらない。
(2)「(体)罰の効果」は学習能力が低い。「褒める」方では、200回で上限に至っているのに、「体罰」の方では、1000回繰り返しても上限に達しない。
ということです。
つまり、「強化学習」のアプローチでは、「体罰」は、拡張性もなく、効率は悪く、効果が低いということです。
しかしながら、体罰に効果を認める人が一定数いるのはなぜか? これは私の(検証のない)仮説ですが、2つ理由があるのではないかと考えています。
(1)「ブロードキャスト」の効果 ―― つまり「見せしめ」です。報酬の方は一人一人を「褒める」必要がありますが、「見せしめ」は一人を痛めつければ、その恐怖が別の人間にも伝搬させることができて、非常に効率が良いのです。
(2)「怒りの発動」を「教育的指導」と言い換えることができる手軽さ ―― 単に「腹を立てて暴力を行っている」という、通常であれば犯罪にもなり得る行動を、「教育的措置を取った」と言い張れる立場を乱用できるわけです(例えば、私が、電車の中で騒いでいるガキを殴ったら、問答無用で、犯罪になります)。
大体、体罰している人間は「お前たちに腹を立てて、叱っているわけではない」という人がいますが、そんなセリフ信じられますか? ―― 冷静に客観的に黙々と体罰を実施できる人間がいれば、それは、教育者以前に人間ではありません。その人、きっと"AI"エンジンを搭載したアンドロイドです。
まあ、ともあれ、「体罰には効果がある」と考える人が一定数いる理由は、おおむね上記の2つの仮説で説明可能であると、私は考えています。
少なくとも、強化学習のQ学習アルゴリズムをそのまま使ってみた限りでは、「(体)罰では効果を発揮できない」ことだけは明らかです。
Copyright © ITmedia, Inc. All Rights Reserved.
記事ランキング
- TSMC撤退の逆風越え、浜松に技術者集結――27年GaN内製化へ全力のローム
- ソニーとimec、次世代3D集積向け裏面接続技術を開発
- AIが食い尽くすメモリ供給 企業ITを揺らす価格高騰
- AMDがメモリ最適化技術の新興を買収 「メモリの壁」を打破できるか
- 次世代チップ積層に関する3つの基盤技術を開発
- ソニー初のLOFIC搭載スマホ用画像センサー 飽和電荷量10倍に
- ADI日本法人新代表が語る「追い風」 AI時代にアナログ半導体が担う役割
- 最高速のガラス微細貫通穴加工技術を開発、理研
- 世界半導体市場が初の単月1000億ドル超え、26年4月
- 宙に浮く透明な会議室? 村田製作所の新拠点から見る「オフィスの現在形」
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。