IBM、8ビット学習が可能なテストチップを発表:「ISSCC 2021」(2/2 ページ)
適切なフォーマットで低精度の学習が可能に
IBMフェローであり、IBM Researchのアクセラレータアーキテクチャ&機械学習部門担当シニアマネジャーも務めるKailash Gopalakrishnan氏は、米国EE Timesのインタビューに応じ、「当社が、長年にわたり手掛けてきた多彩な研究から学んだのは、『低精度トレーニングは非常に難しい課題だが、適切なビット数のフォーマットであれば、8ビットトレーニングを実現することが可能である』ということだ。重要なのは、適切なビット数のフォーマットを把握して、それを深層学習の適切なテンソルに配置することである」と述べている。
実際にHybrid FP8は、2つの異なるフォーマットを組み合わせたものである。1つのフォーマットは、深層学習のフォワードパスでウェイトおよびアクティベーション用として使われている。推論はフォワードパスのみを使用するが、トレーニングはフォワードとバックワードの両方のフェーズを必要とする。
Gopalakrishnan氏は、「われわれが学んだのは、深層学習のフォワードパスにおけるウェイトおよびアクティベーションの表現に関して、より高い忠実度と精度を実現する必要があるということだ。バックワードフェーズの別の側面として、勾配のダイナミックレンジが非常に高いため、より大きな指数が必要であるという点については認識している。これは、深層学習の一部のテンソルにはもっと高い精度と忠誠度による表現が必要とされる一方、他のテンソルにはより大きなダイナミックレンジが必要であることから、矛盾点が生じることになる。これが、当社が2019年末に発表したHybrid FP8フォーマットの起源となる。Hybrid FP8フォーマットは現在、ハードウェアに実装されている」と語った。
IBM Researchの取り組みによって明らかになったのが、フォワードフェーズに関しては、指数と仮数の間で8ビットを分割する時に最適なのは、1-4-3(符号が1ビット、指数が4ビット、仮数が3ビット)であるという点だ。バックワードフェーズに関しては、ダイナミックレンジ232を実現する、5ビットの指数バージョンが代替となる。Hybrid FP8対応のハードウェアは、これら両方のフォーマットをサポート可能な設計を実現している。
研究グループが「階層アキュムレーション(hierarchical accumulation)」と呼ぶイノベーションの実現により、ウェイトとアクティベーションに合わせて精度を下げるためのアキュムレーションが可能になった。一般的にFP16のトレーニング方法は、32ビット計算でアキュムレートすることによって精度を維持するが、IBM Researchの8ビットトレーニングは、FP16でアキュムレートすることが可能だ。FP32でアキュムレーションを維持したことにより、最初にFP8に移行することで得られるメリットが、制限されていたのだろう。
Gopalakrishnan氏は、「浮動小数点演算では、例えば1万ベクトル長のような大量の数字を、全て同時に追加する場合に、浮動小数点表示そのものが合計値の精度を制限し始めるという状況が発生する。このためわれわれとしては、連続的に追加しないということが最善の方法であるという結論に至ったが、長いアキュムレーションを、『チャンク』と呼ばれるグループに分割してしまう傾向にある。そこで、チャンクを相互に追加することにより、このような種類のエラーが生じる可能性を最小限に抑えている」と述べる。
INT4に“容易に”量子化
現在、ほとんどのAI推論はINT8(8ビット整数)を使用している。IBM Researchの研究では、推論精度を大幅に落とさずに低精度にする点では、4ビット整数が最先端であることが示されている。量子化(モデルをより低い精度の数値に変換するプロセス)に続き、Quantization-Aware Training(QAT)が行われる。これは、量子化に起因する誤差を低減するための再トレーニング(最適化)だ。これにより、推論精度の低減を最小限に抑えることができる。IBM Researchの技術では、推論精度の損失を従来に比べて半分に抑えながら、4ビット整数に“容易に”量子化できるとする。
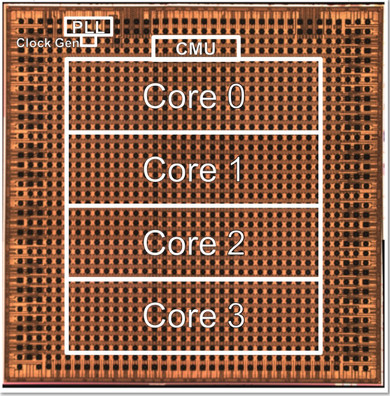 IBM Researchが発表したテストチップ 画像:IBM Research
IBM Researchが発表したテストチップ 画像:IBM Research今回発表したテストチップは、コアの数を変えることでスケールアップ/スケールダウンが可能だ。Gopalakrishnan氏によれば、エッジデバイスには1〜2コア、データセンターには32〜64コアが適しているという。さらに、複数のフォーマット(FP16、Hybrid FP8、INT4、INT2など)をサポートするので、幅広いアプリケーションに応用できると同氏は付け加えた。
【翻訳:田中留美、編集:EE Times Japan】
関連記事
 米半導体企業、大統領に支援を求める書簡を送付
米半導体企業、大統領に支援を求める書簡を送付
主要な半導体企業のCEOが米国バイデン大統領に対して半導体製造/研究に対する財政的支援を優先するよう強く求める書簡に署名したことを受け、ホワイトハウス報道官のJen Psaki氏は、2021年2月8日の週に行われた記者会見の中で、半導体業界は数週間以内に大統領命令への署名を見込めるはずだと述べた。 SDK「Qiskit」で量子コンピュータの利用を促進
SDK「Qiskit」で量子コンピュータの利用を促進
量子コンピュータでは、アクセスのしやすさと使い勝手の良さを両立した開発環境に対するニーズが高まっている。IBMは量子コンピュータ用のSDK(ソフトウェア開発キット)「Qiskit」によって、ユーザーにとって、量子コンピュータの複雑さが分からなくなるほど容易にプログラミングを行える環境の構築を目指している。 IBM、量子ボリュームで自社最高の「64」を達成
IBM、量子ボリュームで自社最高の「64」を達成
IBMは、量子コンピュータの性能を表す「量子ボリューム」という指標で「64」を達成した。自社製品では最高値となる。 量子コンピュータ技術の英新興企業、日本に本格参入
量子コンピュータ技術の英新興企業、日本に本格参入
英ケンブリッジ大学発のベンチャーで、量子コンピューティング技術を手掛けるCambridge Quantum Computing(CQC)は2019年12月19日、本格的に日本市場に進出すると発表した。
Copyright © ITmedia, Inc. All Rights Reserved.
記事ランキング
- TSMC撤退の逆風越え、浜松に技術者集結――27年GaN内製化へ全力のローム
- ソニーとimec、次世代3D集積向け裏面接続技術を開発
- AIが食い尽くすメモリ供給 企業ITを揺らす価格高騰
- AMDがメモリ最適化技術の新興を買収 「メモリの壁」を打破できるか
- 次世代チップ積層に関する3つの基盤技術を開発
- ソニー初のLOFIC搭載スマホ用画像センサー 飽和電荷量10倍に
- 世界半導体市場が初の単月1000億ドル超え、26年4月
- ADI日本法人新代表が語る「追い風」 AI時代にアナログ半導体が担う役割
- 最高速のガラス微細貫通穴加工技術を開発、理研
- 宙に浮く透明な会議室? 村田製作所の新拠点から見る「オフィスの現在形」
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。