脳活動から解読、映像を見て感じた印象も言語化:脳情報デコーディング技術
情報通信研究機構(NICT)脳情報通信融合研究センター(CiNet)は、人の脳活動から、CM映像などを見て感じた内容を、「物体」や「動作」に加え、「印象」まで言葉で読み解くことができる「脳情報デコーディング」技術を開発した。
CMの映像コンテンツ評価用途などに実装
情報通信研究機構(NICT)脳情報通信融合研究センター(CiNet)の西田知史研究員と西本伸志主任研究員は2017年11月、人の脳活動から、CM映像などを見て感じた内容を「物体」や「動作」に加え、「印象」まで言葉で読み解くことができる「脳情報デコーディング」技術を開発したと発表した。
脳情報デコーディングは、人が画像や映像を見て感じたことを、脳活動から読み取る技術。近年は、映像を見て感じた物体と動作の内容について、約500語の単語で言語化し推定した事例も報告されている。ただ、従来技術だと印象まで言語化することはできなかったという。
研究グループは今回、人が映像を見て感じる物体、動作、印象について、その内容を1万語の「名詞」「動詞」「形容詞」として推定する技術を新たに開発した。大規模テキストデータから学習した「言語特徴空間」を、脳活動を解析するためのデコーダーに取り入れて、映像を見て感じた内容の推定に活用することで実現した。言語特徴空間は、意味の近い単語同士を近い距離で、意味の遠い単語であれば遠い距離でそれぞれ表現する。今回は1万語の表現を持つ言語特徴空間を取り入れた。これにより、従来技術に比べ20倍の単語を用いて解読が可能となったという。
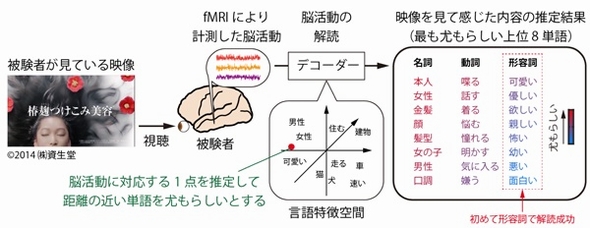 映像を見て感じた内容解読の一例 出典:NICT
映像を見て感じた内容解読の一例 出典:NICT具体的には、機能的磁気共鳴画像法(fMRI)を用いて、映像を視聴している被験者の脳活動を約2時間計測し、言語特徴空間を介して1万単語の近さや遠さを推定する。一方で、同じ映像内の各シーンに対して、被験者とは別の人たちにもシーンを説明する言語記述を行ってもらい、それぞれが感じる内容を文章にして評価した。シーン記述は、事前にWikipediaの大規模テキストデータに基づいて学習した言語特徴空間の表現に変換し、シーン記述の言語特徴表現(言語特徴ベクター)を作製した。
今回の研究では、2013年にGoogleの研究者が開発した「Word2Vec」と呼ばれる技術を言語特徴空間の学習に利用し、言語特徴空間を100次元のベクター空間として表現した。このため、1つのシーン記述は言語特徴空間内の1点に対応する100次元の特徴ベクターに変換される。実験で計測した脳活動と、それに対応する特徴ベクターのデータに、機械学習を適用することで、脳活動と言語特徴空間の対応関係を推定し、それを重み係数として保持する。
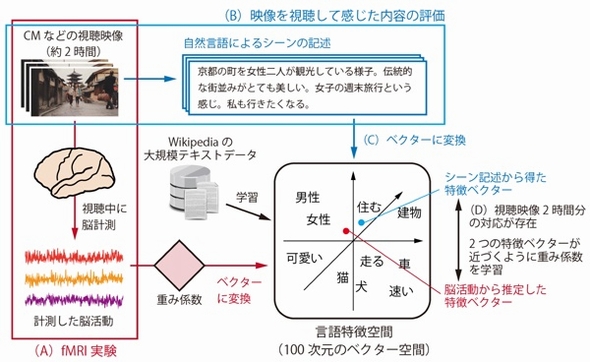 デコーダー構築の概要図 出典:NICT
デコーダー構築の概要図 出典:NICT次に、構築したデコーダーを用いて、被験者が映像を見て感じた内容を単語の形で推定する。脳活動から推定した特徴ベクターと1万単語の特徴ベクターの相関関係を−1から1の値で評価する。これが1に近いほど類似度が高いことを示すという。こうした類似度に基づいて、映像を見て感じた物体や動作、印象の内容を単語の形で推定する。
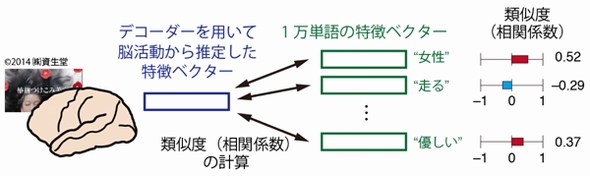 デコーダーを用いて推定した特徴ベクターを基に、映像を見て感じた内容と類似する単語を推定 出典:NICT
デコーダーを用いて推定した特徴ベクターを基に、映像を見て感じた内容と類似する単語を推定 出典:NICTデコーダーによる推定の正確さを評価するため、研究グループは類似度の検証も行った。この結果、6人の被験者で相関係数は0.40〜0.45の値となり、十分に高い類似度を示すことを確認した。
今後は、映像から感じた内容の推定精度をさらに向上させるとともに、CM映像などが個性や購買行動にどう結び付くのか、などの検証にも取り組む予定である。さらに、発話や筆談が困難な人たちも利用できるよう、発話を介しない言語化コミュニケーション技術についても、産官学の連携で研究を行う計画である。
なお、開発した技術はNTTデータにライセンス提供され、「脳情報デコーディング技術に基づいたCMなどの映像コンテンツ評価サービス」として、2016年度より実用化されている。
関連記事
 NICT、53.3Tbpsの光信号高速スイッチングに成功
NICT、53.3Tbpsの光信号高速スイッチングに成功
情報通信研究機構(NICT)ネットワークシステム研究所は、光ファイバーで伝送されたパケット信号の経路を切り替える光交換技術において、従来の世界記録を4倍以上更新し、53.3Tbpsの光信号スイッチング実験に成功した。 NICT、超小型衛星で量子通信の実証実験に成功
NICT、超小型衛星で量子通信の実証実験に成功
情報通信研究機構(NICT)は、超小型衛星による量子通信の実証実験に世界で初めて成功した。実験に使用した衛星は重さ50kgで大きさは50cm角と、衛星量子通信用途では最も軽量かつ小型だという。 NICT、深紫外LEDで実用域の光出力を達成
NICT、深紫外LEDで実用域の光出力を達成
情報通信研究機構(NICT)は、発光波長265nm帯で光出力が150mWを上回る「深紫外LED」の開発に成功した。産業用途で十分に利用可能な出力レベルだという。 地デジ放送波でゲリラ豪雨を予測? NICTが開発
地デジ放送波でゲリラ豪雨を予測? NICTが開発
情報通信研究機構(NICT)は、地上デジタル放送の電波を用いた水蒸気推定手法の開発に成功したと発表した。ゲリラ豪雨など局所的な気象現象の予測精度向上につながることが期待される。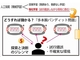 半導体レーザーのカオス現象で強化学習を高速化
半導体レーザーのカオス現象で強化学習を高速化
情報通信研究機構(NICT)の成瀬誠主任研究員らによる研究グループは、半導体レーザーから生じるカオス現象を用い、「強化学習」を極めて高速に実現できることを実証した。 見通し外の位置にいるドローンの制御が可能に
見通し外の位置にいるドローンの制御が可能に
情報通信研究機構(NICT)は「テクノフロンティア2017」で、障害物を迂回してドローンに電波を届けるマルチホップ無線通信システム「タフワイヤレス」と、ドローン間位置情報共有システム「ドローンマッパー」を発表した。前者は、発信地から見て見通し外の場所にいるドローンを制御するためのシステム。後者は、ドローン同士の衝突を防止するためのシステムだ。
Copyright © ITmedia, Inc. All Rights Reserved.
記事ランキング
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。