性能と演算量を調整可能なスケーラブルAI技術:2023年までの実用化を目指す
東芝と理化学研究所(理研)は、学習済みAIの性能をできる限り落とさずに、演算量を調整できる「スケーラブルAI技術」を開発した。プロセッサの処理能力が異なる応用システムの場合でも、AIエンジンの共有化が可能となる。
演算量を1/3に削減しても、分類性能の低下率を2.1%に抑える
東芝と理化学研究所(理研)は2021年8月、学習済みAI(人工知能)の性能をできる限り落とさずに、演算量を調整できる「スケーラブルAI技術」を開発したと発表した。プロセッサの処理能力が異なる応用システムの場合でも、AIエンジンの共有化が可能となる。
AIエンジンは、適用するシステムやサービスに合わせて、AIのモデルサイズなどを設計/開発していた。このため、開発に必要な期間やコストが増え、課題となっていた。しかも、個別対応となるため、その管理も煩雑になっていたという。
これらの課題を解決する手法として、「スケーラブルAI」が注目されている。利用するシステムの演算能力に応じて、単一のAIを展開することができるからだ。しかし現状では、「演算量を落とすとAI性能も低下する」という課題があったという。
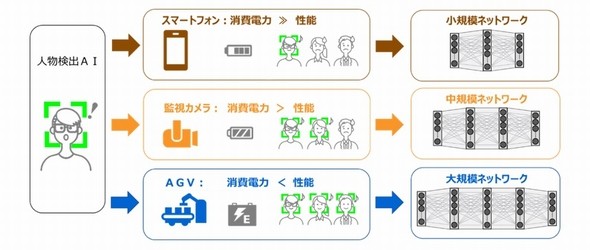
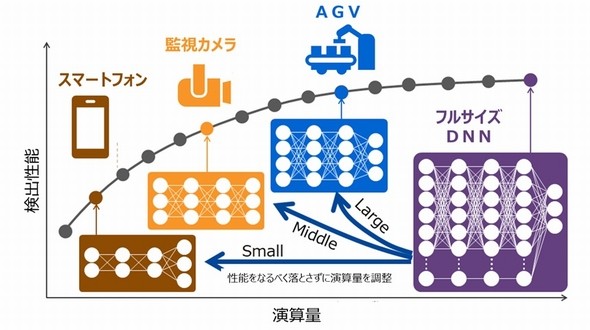 上図は新技術を開発した背景、下図はスケーラブルAIの効果 出典:東芝、理研
上図は新技術を開発した背景、下図はスケーラブルAIの効果 出典:東芝、理研そこで東芝と理研は、2017年4月に設立した「理研AIP−東芝連携センター」で、性能の低下を抑えて演算量を調整できる、スケーラブルAI技術の開発を行ってきた。そして、独自の深層学習技術により、学習済みのAIがその性能を維持しつつ、処理能力が異なるプロセッサでも動作可能な技術を開発した。
具体的には、フルサイズの深層ニューラルネットワーク(フルサイズDNN)を、誤差が出ないように近似した「小さな行列」に分解し、演算量を削減する「コンパクトDNN」を用いる。従来のコンパクトDNNと異なるのは、演算量を削減する方法だ。
これまでは、全ての層で行列の一部を一律に削除していた。開発した技術は、重要な情報が多い層の行列をできるだけ残しながら演算量を削減する。これによって、近似による誤差を極めて小さくすることに成功した。
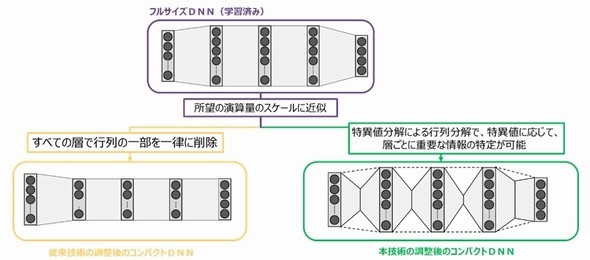 開発した技術の特長 出典:東芝、理研
開発した技術の特長 出典:東芝、理研学習中は、演算量が異なるさまざまなコンパクトDNNからの出力と、フルサイズDNNからの出力の差が小さくなるよう、フルサイズDNNの重みを更新する。これによって、あらゆる演算量の大きさで、バランスよく学習できるという。
学習後は、適用するシステムに適したコンパクトDNNへと、フルサイズDNNを展開することが可能である。さらに、学習によって演算量と性能の対応関係が可視化され、組み込みシステムに搭載するプロセッサの選択が容易になるという。
実験では、著名な一般画像の公開データを用い、被写体に応じてデータを分類するタスクの精度を評価した。この結果、学習したフルサイズDNNから演算量を1/2、1/3および、1/4に削減しても、分類性能の低下率はそれぞれ1.1%、2.1%、3.3%に抑えることができたという。ちなみに、従来のスケーラブルAIによる低下率は、それぞれ2.7%、3.9%、5.0%であった。
東芝と理研は今後、開発した技術をハードウェアアーキテクチャに対して最適化。その上で、エッジデバイスなどへの適用を進め、その有効性を検証していく。2023年までには実用化したい考えである。
関連記事
 安全な半導体回路情報を共有するシステムを検証
安全な半導体回路情報を共有するシステムを検証
KDDI総合研究所と東芝情報システムは、安全で安心な半導体回路であることを、サプライチェーン上の組織間で共有する仕組みについて、実証実験を行う。 開発プラットフォーム向けコネクター技術を評価
開発プラットフォーム向けコネクター技術を評価
東芝デバイス&ストレージは、IoT機器を簡単に試作できる開発プラットフォーム「トリリオンノード・エンジン」向けのコネクター技術を評価した。この技術を用いると、はんだ付けなどの作業をしなくても、容易に接続部の実装が可能となる。 東芝、ソリッドステートLiDAR向け受光技術を開発
東芝、ソリッドステートLiDAR向け受光技術を開発
東芝は、「ソリッドステート式LiDAR」向けの受光技術と実装技術を新たに開発した。新技術を採用すると、200mの最長測定距離を維持しつつ、従来に比べサイズが3分の1で、解像度は4倍となるLiDARを実現できるという。 量子技術の産業化を加速、日本企業11社が協議会設立
量子技術の産業化を加速、日本企業11社が協議会設立
東芝、富士通、トヨタ自動車などの民間企業11社は2021年5月31日、量子技術の研究開発と社会実装の加速を目指す協議会「量子技術による新産業創出協議会」の設立発起人会を開催した。 理研ら、機械学習法で「量子スピン液体」を解明
理研ら、機械学習法で「量子スピン液体」を解明
理化学研究所(理研)らの共同研究チームは、機械学習を用いて「量子スピン液体」を解明した。スーパーコンピュータ「富岳」などを活用して大規模計算を行い実現した。 第一原理計算で結晶の性質を解析する手法を開発
第一原理計算で結晶の性質を解析する手法を開発
理化学研究所(理研)と大阪大学の共同研究チームは、ニューラルネットワークを用いて、固体結晶の電子状態に関する第一原理計算を、精密に行うことができる新たな手法を開発した。
Copyright © ITmedia, Inc. All Rights Reserved.
記事ランキング
- TSMC撤退の逆風越え、浜松に技術者集結――27年GaN内製化へ全力のローム
- ソニーとimec、次世代3D集積向け裏面接続技術を開発
- AIが食い尽くすメモリ供給 企業ITを揺らす価格高騰
- AMDがメモリ最適化技術の新興を買収 「メモリの壁」を打破できるか
- 次世代チップ積層に関する3つの基盤技術を開発
- ソニー初のLOFIC搭載スマホ用画像センサー 飽和電荷量10倍に
- ADI日本法人新代表が語る「追い風」 AI時代にアナログ半導体が担う役割
- 世界半導体市場が初の単月1000億ドル超え、26年4月
- 最高速のガラス微細貫通穴加工技術を開発、理研
- 宙に浮く透明な会議室? 村田製作所の新拠点から見る「オフィスの現在形」
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。