隠れニューラルネットワーク理論に基づく推論LSI:オンチップモデル構築で転送量半減
東京工業大学は、「隠れニューラルネットワーク」理論に基づいた「推論アクセラレータLSI」を開発した。新提案のオンチップモデル構築技術により、外部メモリへのアクセスを大幅に削減。世界最高レベルの電力効率と推論精度を実現した。
演算効率は最大34.8TOPS/W、推論精度はImageNet70.1%を達成
東京工業大学科学技術創成研究院の劉載勲准教授や本村真人教授らによる研究チームは2022年2月、「隠れニューラルネットワーク(Hidden Neural Network)」理論に基づいた「推論アクセラレータLSI」を開発したと発表した。新提案の「オンチップモデル構築(On-chip Model Construction)」技術により、外部メモリへのアクセスを大幅に削減。世界最高レベルの電力効率と推論精度を実現した。
深層ニューラルネットワーク(DNN)と呼ばれる人間の脳を模した情報処理モデルを用い、画像や映像情報から状況を判断する深層学習(ディープラーニング)は、自動運転車やロボット、顔認証などの分野で、活用が期待されている。ところが、推論に必要となる情報量が爆発的に増加し、計算時の電力消費が増えるため、自動車やドローンなど移動機器では課題となっていた。
2020年には、軽量なDNNモデルを実現する技術として「隠れニューラルネットワーク」理論が登場した。今回の研究では、この隠れニューラルネットワーク理論に着目。「重みを学習しない」「スーパーマスクで部分ネットワークを発掘する」という、これまでのDNNにない2つの特長を備えたDNN推論アクセラレータを実現した。
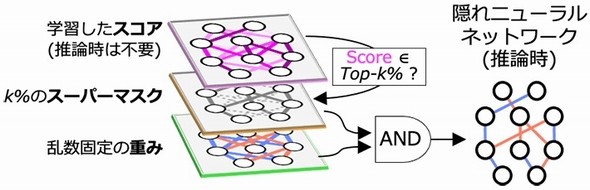 隠れニューラルネットワーク理論の概念図 出所:東京工業大学
隠れニューラルネットワーク理論の概念図 出所:東京工業大学研究チームは今回、隠れニューラルネットワーク理論を効率的に扱うことができる「ヒデナイト(Hiddenite:Hidden Neural Network Inference Tensor Engine)」と呼ぶハードウェアアーキテクチャを考案。そして実際にTSMCの40nmプロセスを用い、推論アクセラレータLSIを試作した。
新たに開発した推論アクセラレータLSIは、二値の重みとスーパーマスクが必要となるため、モデルサイズは二値化ネットワークの2倍となる。しかし、「オンチップモデル構築」技術により、二値化ネットワークに比べ転送量を約半分に減らすことができ、全体の電力消費も大幅に削減できるという。
 従来技術とヒデナイトによる推論LSIのデータ転送量比較 出所:東京工業大学
従来技術とヒデナイトによる推論LSIのデータ転送量比較 出所:東京工業大学ヒデナイトは、重みとスーパーマスクがそれぞれ1ビットであるため乗算器を必要とせず、ニューロン演算器を多数配置して並列演算を行うことができる。この能力を生かすため、畳み込みニューラルネットワークの4次元(入力チャネル数、特徴マップの高さ、特徴マップの幅、出力チャネル数)方向に、バランスよく割り当てる工夫も行った。
 ヒデナイトアーキテクチャの概略 出所:東京工業大学
ヒデナイトアーキテクチャの概略 出所:東京工業大学試作した推論アクセラレータLSIのチップサイズは3×3mmで、4096個のニューロン演算器を並列動作させ、4次元の並列性を生かした高速推論処理を行うことができる。DNNモデルの転送量を二値化ネットワークの半分に抑えながら、最大34.8TOPS/Wの演算効率を実現。しかも、この時の消費電力は約40mWと極めて小さい。推論精度もImageNet70.1%で、従来と同等の値を達成したという。
 隠れニューラルネットワーク理論に基づくDNN推論アクセラレータLSIの外観 出所:東京工業大学
隠れニューラルネットワーク理論に基づくDNN推論アクセラレータLSIの外観 出所:東京工業大学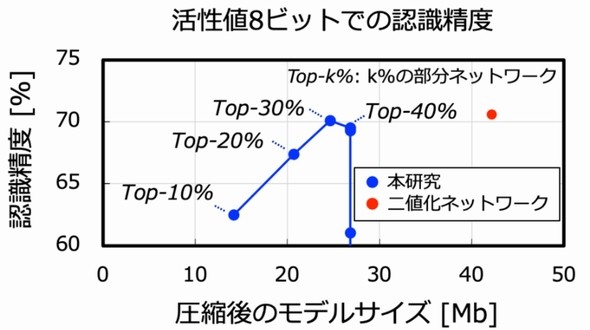 今回実現したモデルサイズと認識精度および、従来技術との比較(Resnet50、ImageNet、活性値8ビット) 出所:東京工業大学
今回実現したモデルサイズと認識精度および、従来技術との比較(Resnet50、ImageNet、活性値8ビット) 出所:東京工業大学関連記事
 Beyond 5G向けデバイスの研究開発を本格開始
Beyond 5G向けデバイスの研究開発を本格開始
シャープ、シャープセミコンダクターイノベーション(SSIC)、東京大学大学院工学系研究科、東京工業大学、日本無線の5者は、Beyond 5G(B5G)向けIoT(モノのインターネット)ソリューション構築プラットフォームの研究開発を本格的に始める。産官学が協力し、B5Gの用途拡大と国際競争力の強化を図る。 MEMS技術を用い電子部品の薄型・小型化を実現
MEMS技術を用い電子部品の薄型・小型化を実現
新エネルギー・産業技術総合開発機構(NEDO)とアルファー精工、旭電化研究所および、シナプスは、MEMS技術を用い、薄型かつ小型で優れた伝送特性を備えた電子部品の開発に成功した。素材として金属と樹脂を用いるため、第6世代移動通信(6G)システム向けのコネクターやソケットなどに適用することができる。 東京工大、溶液法で高性能のpチャネルTFTを開発
東京工大、溶液法で高性能のpチャネルTFTを開発
東京工業大学は、溶液法を用いて、優れた半導体特性を有する「pチャネル薄膜トランジスタ(TFT)」の開発に成功した。新規開発の材料ではなく、既存の物質同士をうまく組み合わせることによって実現した。 低下した全固体電池の性能を加熱処理で大幅改善
低下した全固体電池の性能を加熱処理で大幅改善
東京工業大学は、東京大学や産業技術総合研究所、山形大学らと共同で、低下した全固体電池の性能を、加熱処理だけで大幅に改善させる技術を開発した。電気自動車用電池などへの応用が期待される。 東京工大ら、SOT-MRAM素子の原理動作実証に成功
東京工大ら、SOT-MRAM素子の原理動作実証に成功
東京工業大学と米国カリフォルニア大学ロサンゼルス校を中心とした国際研究チームは、トポロジカル絶縁体と磁気トンネル接合(MTJ)を集積したスピン軌道トルク磁気抵抗メモリ(SOT-MRAM)素子を試作し、読み出しと書き込みの原理動作を実証した。 レドックス・フロー熱電発電で発電密度を1桁向上
レドックス・フロー熱電発電で発電密度を1桁向上
東京工業大学の研究グループは、排熱源を冷却しながら発電を行う「レドックス・フロー熱電発電」で、従来に比べ発電密度を1桁以上高くすることに成功した。
関連リンク
Copyright © ITmedia, Inc. All Rights Reserved.
記事ランキング
- TSMC撤退の逆風越え、浜松に技術者集結――27年GaN内製化へ全力のローム
- ソニーとimec、次世代3D集積向け裏面接続技術を開発
- AIが食い尽くすメモリ供給 企業ITを揺らす価格高騰
- AMDがメモリ最適化技術の新興を買収 「メモリの壁」を打破できるか
- 次世代チップ積層に関する3つの基盤技術を開発
- ソニー初のLOFIC搭載スマホ用画像センサー 飽和電荷量10倍に
- 世界半導体市場が初の単月1000億ドル超え、26年4月
- ソニーが新画素構造「RB2×2 OCL」採用センサー 高解像度とAF性能を両立
- 宙に浮く透明な会議室? 村田製作所の新拠点から見る「オフィスの現在形」
- ADI日本法人新代表が語る「追い風」 AI時代にアナログ半導体が担う役割
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。