20ストリームの画像データを同時に処理できるSoC:Ambarellaの車載SoC(2/2 ページ)
第3世代CVFlowアクセラレーターエンジンを搭載
AmbarellaのCV3-High SoCは、照明/運転状況が厳しい環境でも動作可能な、イメージシグナルプロセッサを搭載する。また、ステレオカメラを処理するためのステレオ/高密度オプティカルフローアクセラレーターの他、Armの「Cortex-A78AE」を16個と、セーフティアイランド、ビデオコーデックなども備える。GPUは主にパーキングアシストに向けたセンサー出力の視覚表示をレンダリングするために使われている。
 Ambarella「CV3」のブロック図。CVFlowエンジンの最上部で動作するのは、16個のArmコア「Cortex-A78AE」と、ステレオ/高密度オプティカルフロープロセッサ、イメージシグナルプロセッサ、ビデオコーデック、GPUである[クリックで拡大] 出所:Ambarella
Ambarella「CV3」のブロック図。CVFlowエンジンの最上部で動作するのは、16個のArmコア「Cortex-A78AE」と、ステレオ/高密度オプティカルフロープロセッサ、イメージシグナルプロセッサ、ビデオコーデック、GPUである[クリックで拡大] 出所:Ambarella第3世代のCVFlowアクセラレーターエンジンが同シリーズで実装されるのは、今回が初めてである。旧世代のCVFlowエンジンとは対照的に、2つのブロックで構成されている。1つは、AIワークロードに対応するためのニューラルベクトルプロセッサ(NVP:Neural Vector Processor)で、もう1つは、浮動小数点対応の汎用ベクトルプロセッサ(GVP:General Vector Processor)だ。コンピュータビジョンワークロードはNVPから、浮動小数点ワークロードはArm CPUからオフロードされる。例えば、レーダー処理はGVPで対応し、知覚はNVPで実行することになる。いずれのブロックも、社内IPをベースとしている。
NVPと新しいGVPとの間でワークロードを分割することにより、NVPでは、畳み込み処理やマトリクス処理をさらに最適化することが可能になる。
Kohn氏は、「内部メモリシステムとそのシステム間のインターコネクトを最適化することにより、ボトルネックを取り除いて効率性を高められた他、内部のデータパスも全て再最適化することができた。つまり、アーキテクチャの根本的な変更というより、細部を修正することで、ボトルネックを取り除いてコアネットワーク処理を最適化したということだ」と述べる。
またNVPバージョンは、グラフネットワークやトランスフォーマーなどのリアルタイムアプリケーション向けとして最近使われ始めた高性能ネットワークに共通した演算も追加している。
NVPは、500eTOPSの8ビット性能または1000eTOPSの4ビット性能を達成する(Kohn氏によると、より現実的なシナリオとしては、別のネットワークレイヤーで使われる場合の精度が混在した状態になるという)。Ambarellaの第2世代SoCと比べると、性能は42倍向上した。
同製品ファミリーのデバイスは将来的に、CVFlowエンジンのサイズや、イメージパイプラインのエンコーディング、複数の周辺機器などが拡大していくだろう。またソフトウェアについては、エントリーモデルやミドルクラス、高級車などでも使えるよう、CV3ファミリー全体で移行されていくとみられる。
CV3-High全体の消費電力量は約50Wで、旧世代品と比べるとワット当たりの性能は4倍高い。その要因の1つとしては、5nmプロセス技術への移行が挙げられる。
AmbarellaのCV3ファミリーにとって初となるSoCは、2022年前半にサンプル出荷が開始される予定だ。
【翻訳:田中留美、編集:EE Times Japan】
関連記事
 14ビデオストリーム上でAIを同時に実行可能なSoC
14ビデオストリーム上でAIを同時に実行可能なSoC
イメージプロセッサの専業メーカーであるAmbarellaは、新型SoC(System on Chip)「CV5S」と「CV52S」の2品種を発表した。 新カテゴリー「ホームビジョンシステム」でのメモリの選び方
新カテゴリー「ホームビジョンシステム」でのメモリの選び方
ホームビジョンシステムという新たなカテゴリーにおいてどのようにDRAMテクノロジーを選択するべきかを検証し、ISPベースアーキテクチャの要求に対して、DRAMメーカーがどのように対応しているかを説明します。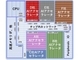 複数AIアクセラレーター搭載の評価チップを試作
複数AIアクセラレーター搭載の評価チップを試作
新エネルギー・産業技術総合開発機構(NEDO)と産業技術総合研究所(産総研)および、東京大学は共同で、仕様が異なる6種類のAIアクセラレーターを搭載した評価チップ「AI-One」を設計、試作を始めた。これを活用すると、短い期間で安価にAIチップの設計と評価が可能になる。 AIアクセラレーターはデータセンターの省エネに貢献可能か
AIアクセラレーターはデータセンターの省エネに貢献可能か
データセンターでは機械学習関連のワークロードが増えているが、AI(人工知能)アクセラレーターを使うことは、省エネにつながるのだろうか。 “CPU大国への道”を突き進む中国、ドローン分解で見えた懸念
“CPU大国への道”を突き進む中国、ドローン分解で見えた懸念
中国DJIのドローン「Phantom 4」には、28個ものCPUが搭載されている。CPUの開発で先行するのは依然として米国だが、それを最も明確に追っているのは中国だ。だが分解を進めるにつれ、「搭載するCPUの数を増やす」方法が、機器の進化として、果たして正しい方向なのだろうかという疑問が頭をよぎる。 車載ビジョン市場における競争が加速
車載ビジョン市場における競争が加速
イメージセンサーやビジョンSoC、センサーフュージョンなど、ADAS(先進運転支援システム)向け技術開発における競争が加速している。
Copyright © ITmedia, Inc. All Rights Reserved.
記事ランキング
- ソニーが新画素構造「RB2×2 OCL」採用センサー 高解像度とAF性能を両立
- TSMC撤退の逆風越え、浜松に技術者集結――27年GaN内製化へ全力のローム
- AIが食い尽くすメモリ供給 企業ITを揺らす価格高騰
- 次世代チップ積層に関する3つの基盤技術を開発
- AmazonはNVIDIAに挑戦状を突きつけるのか
- 世界半導体市場が初の単月1000億ドル超え、26年4月
- 車載は「新たな成長段階に」 SiCパワー半導体市場、5年後110億ドル規模へ
- 宙に浮く透明な会議室? 村田製作所の新拠点から見る「オフィスの現在形」
- パッケージ基板の配線微細化と歩留まりを両立させる新製法
- 反りも割れも抑制 先端パッケージ向け多層セラミックコア基板
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。