FeFETによる機械学習、音声認識の精度は95.9%:現行製造プロセスとも高い親和性
東京大学は、強誘電体トランジスタ(FeFET)を用いた「リザバーコンピューティング」と呼ばれる機械学習方式を開発し、高い精度で音声認識を行うことに成功した。採用したFeEFTは現行の製造プロセスと親和性が高く、LSIの大規模化も比較的容易とみている。
3つの電流成分の時間応答を組み合わせる方式などを採用
東京大学は2022年6月、強誘電体トランジスタ(FeFET)を用いたリザバーコンピューティングと呼ばれる機械学習方式を開発し、高い精度で音声認識を行うことに成功したと発表した。採用したFeEFTは現行の製造プロセスと親和性が高く、大規模LSIにも比較的対応が容易とみている。
研究グループはこれまで、酸化ハフニウム系強誘電体材料を用いて製造するFeFETを活用したリザバーコンピューティング方式を提案し、その基本動作について確認してきた。ただ、実用化に向けた計算性能の確認や、システム上の課題などについての十分な検証までは至っていなかったという。
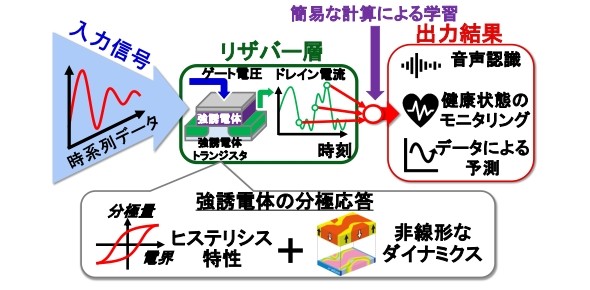 FeFETを用いたリザバーコンピューティングの模式図 出所:東京大学
FeFETを用いたリザバーコンピューティングの模式図 出所:東京大学そこで今回、音声認識への適用を想定し、新たなリザバーコンピューティング方式を提案し、認識率を向上させるための工夫なども行って、その有効性を検証した。作製したMOSFETは、膜厚0.7nmの「SiO2」と、ゲート絶縁膜として膜厚が10.5nmの「Hf0.5Zr0.5O2(HZO)」を、Si基板上に積層した。
 HZO/Si FeFETの素子構造(左)と電流−ゲート電圧特性(右) 出所:東京大学
HZO/Si FeFETの素子構造(左)と電流−ゲート電圧特性(右) 出所:東京大学作製したMOSFETは、時系列データに対応する入力信号を、ゲート電圧として印加することにより、HZO膜の分極状態を制御することができる。そして、分極の記憶特性や分極が時間的に変化する特性を、トランジスタの電流の時間応答特性として読み出し、これらのパターンを機械学習の手法により分類すれば、時系列入力データが含む情報に対して、学習や推論を行うことができるという。
今回の研究では、FeFETの「ドレイン電流」や「ソース電流」「基板電流」に対する時間応答を組み合わせて学習、推論する方式を提案し、その有効性を検証した。FeFETを用いた物理リザバーコンピューティングの基礎的性能を向上させるためである。
認識精度を検証するため、「0」から「9」までの数字について英語で発話し、その認識率を確認した。具体的には、発話の音声データを複数の周波数に分割した時系列データとして扱う。これらをゲート電圧として、それぞれFeFETのゲート電極に入力して並列処理を行い、各FeFETでの推論結果について、多数決を取り推論を行う方式である。
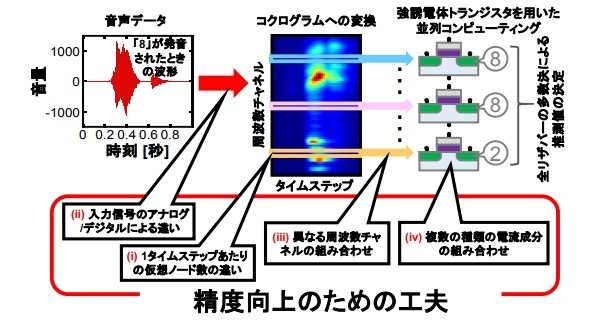 音声数字認識を行うためのFeFETリザバーコンピューティングと、認識精度を向上させるアプローチの概念図 出所:東京大学
音声数字認識を行うためのFeFETリザバーコンピューティングと、認識精度を向上させるアプローチの概念図 出所:東京大学音声発話を特徴的な周波数に分割して並列処理を行うことで、推論を高速に行うことが可能となった。さらに、時系列データに対する電流応答を読み出す時間の刻みを最適化し、ゲート電極への入力をアナログ入力とすることで、認識精度が高まることを示した。さらに、「周波数チャネルの組み合わせ方法の最適化」と、「ドレイン電流、ソース電流、基板電流の時間応答を用いる方法」を組み合わせることで、音声認識率として95.9%を達成することができた。
 FeFETリザバー・コンピューティング方式の改良に伴う認識精度の向上と直接線形回帰およびソフトウェアリザバーとの比較 出所:東京大学
FeFETリザバー・コンピューティング方式の改良に伴う認識精度の向上と直接線形回帰およびソフトウェアリザバーとの比較 出所:東京大学今回の研究成果は、東京大学大学院工学系研究科電気系工学専攻の名幸瑛心大学院生とKasidit Toprasertpong講師、中根了昌特任准教授、竹中充教授および、高木信一教授らによるものである。
関連記事
 ALD法で酸化物半導体を三次元構造へ均一に成膜
ALD法で酸化物半導体を三次元構造へ均一に成膜
東京大学と奈良先端科学技術大学院大学の共同研究グループは、酸化インジウムの成膜に原子層堆積(ALD)法を用いる技術を開発、この技術を活用して三次元垂直チャネル型の強誘電体/反強誘電体トランジスタメモリを開発した。 生体呼気で個人認証、東京大らが原理実証に成功
生体呼気で個人認証、東京大らが原理実証に成功
東京大学と九州大学、名古屋大学および、パナソニック インダストリーの研究グループは、「生体呼気」で個人認証を行う原理実証に成功した。20人を対象に行った実験では、97%以上の精度で個人を識別できたという。【訂正あり】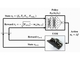 深層強化学習法により、超音波モーターを最適制御
深層強化学習法により、超音波モーターを最適制御
東京大学は、深層強化学習法を用いて、超音波モーターを最適駆動する制御システムを開発した。超音波モーターを手術ロボティックスや触覚提示システムなどへ搭載することが可能になるという。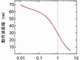 東京大ら、トポロジカル導波路の広帯域化を可能に
東京大ら、トポロジカル導波路の広帯域化を可能に
東京大学と慶應義塾大学、電磁材料研究所の研究グループは、ENZ特性を持つ磁気光学材料を用いることで、帯域が広いトポロジカル導波路を実現できることを明らかにした。光回路のさらなる高密度高集積化が可能となる。 東京大ら、テラヘルツ領域の光起電力効果を観測
東京大ら、テラヘルツ領域の光起電力効果を観測
東京大学と理化学研究所らの研究グループは、強誘電体「BaTiO3(チタン酸バリウム)」を用い、テラヘルツ光照射による光電流の観測に成功した。可視光の約1000分の1の光エネルギーで発電が可能になるという。 結晶対称性を反映した新原理の超伝導整流現象を発見
結晶対称性を反映した新原理の超伝導整流現象を発見
東京大学の研究グループは、埼玉大学や東京工業大学のグループと共同で、空間反転対称性の破れた超伝導体「PbTaSe2」において、外部磁場がなくても巨大な整流特性を示すことを発見し、その微視的な機構を明らかにした。
関連リンク
Copyright © ITmedia, Inc. All Rights Reserved.
記事ランキング
- TSMC撤退の逆風越え、浜松に技術者集結――27年GaN内製化へ全力のローム
- AIが食い尽くすメモリ供給 企業ITを揺らす価格高騰
- ソニーとimec、次世代3D集積向け裏面接続技術を開発
- ソニーが新画素構造「RB2×2 OCL」採用センサー 高解像度とAF性能を両立
- 次世代チップ積層に関する3つの基盤技術を開発
- AMDがメモリ最適化技術の新興を買収 「メモリの壁」を打破できるか
- ソニー初のLOFIC搭載スマホ用画像センサー 飽和電荷量10倍に
- 世界半導体市場が初の単月1000億ドル超え、26年4月
- 宙に浮く透明な会議室? 村田製作所の新拠点から見る「オフィスの現在形」
- 最高速のガラス微細貫通穴加工技術を開発、理研
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。