株価データベースを「Docker」で作ってみる:「お金に愛されないエンジニア」のための新行動論(4)(10/12 ページ)
CSVファイルとDockerを使ってデータベースを作成してみよう
では、ここから、このCSVファイルとdockerを使った株情報のデータベースを作成してみたいと思います。
ここでは、私と同じ環境を持っていることを前提に話を進めます。あなたのPCのOSがWindows 10で、Docker for Windowsがインストールされているものとします。インストール方法は、こちらのページをご参照ください。また、Go言語の環境もインストールされているものとします(参考)。
次に、こちらから、適当なディレクトリに、ファイル一式をダウンロードしてください(取得済みのcsvファイルも入っています)。
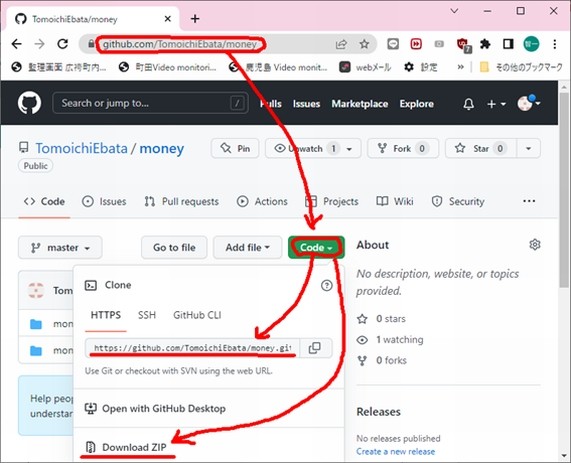
Zipファイルでダウンロードしても良いですが、この機会に、あなたのPCにgitがあると、いろいろ幸せになれます。gitは、”git” “install” “windows”でググって頂き、サクっとインストールできると思います。
gitをインストールした後、
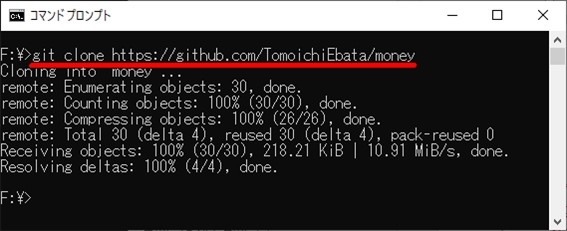
$ git clone https://github.com/TomoichiEbata/money
のコマンド一発で、私と同じ環境が、あなたのPCに構築されます。
現在、moneyというディレクトリに、
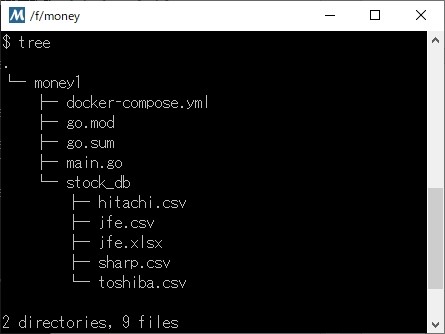
のような、ディレクトリとファイルができています。stock_dbに格納されている、”hitachi.csv”, “sharp.csv”, “toshiba.csv”, “jfe.csv”は、SBI証券のサイトからダウンロードした株価情報です。
さて、ここからdockerコンテナの作成に入ります。
まず、ダウンロードしたディレクトリに入ります(私の場合、f:\money)。ここから、
$ cd money1
で、money1のディレクトリに入ります。
ここで、
$ docker-compose -up d
で、データベース用Dockerコンテナが作成されます。
このコンテナを作成する設計図になっている”docker-compose.yml”の内容です。
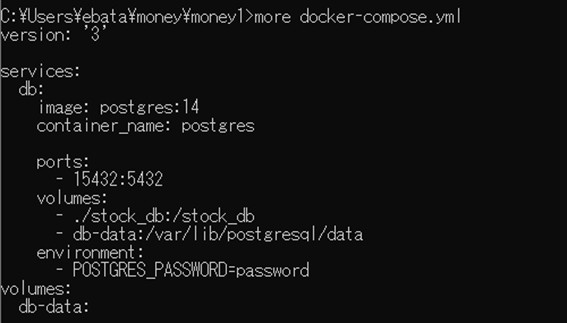
上記の設計図の内容を簡単に説明すれば、(1)postgreSQLというデータベースを含むコンテナを作成し、(2)そのデータベースは、ポート番号15432でアクセスできて、(3)money\money1\stock_dbというディレクトリの内容を共有できて、(4)データベースのログインパスワードは、”password”である、ということです。
正直、docker-compose.ymlの内容は(というか、dockerそのものが)結構面倒くさいです(筆者のブログ)。参考にはなりませんが、私の苦労した記録ならこちらにあります。
さて、
$ docker-compose start
で、Dockerコンテナを起動してください。
$ docker-compose ps
で、以下のような内容が表示されていれば、起動に成功しています。
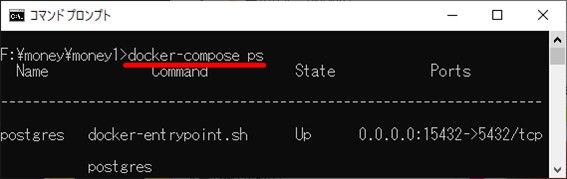
さて、現時点でPostgreSQLのデータベースは稼働状態になっていますので、psqlなどのクライアントを使えばログインできますが、さらにpsqlをインストール(インストール手順はこちら)するのも面倒だと思いますので、このままDockerコンテナに入ってしまいましょう。
$ docker exec -it postgres bash
で、Dockerコンテナの中に入れます。
さらに、ここから、postgreSQLのデータベースの中に入ります。
# psql -U postgres

今回は、日立製作所、東芝、JFEホールディングスの3社の株価情報DBを作成します(この3社を選んだのは、単に、江端の趣味です)。
Postgres=# create database hitachi;
で、”hitachi”という名前のDBを作成したら、さらに、そのDBの中に入ります。
postgres=# \c hitachi
これで、”hitachi”に入れました。
ここで、このhitachiのDBのテーブル(データを入れる容器)を作ります*)。
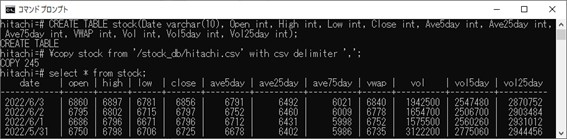
hitachi=# CREATE TABLE stock(Date varchar(10), Open int, High int, Low int, Close int, Ave5day int, Ave25day int, Ave75day int, VWAP int, Vol int, Vol5day int, Vol25day int);
(改行しないで、一行で投入してください)
*)こちらのページの記載をコピペしてご利用ください
これは、先程ダウンロードした、csvファイルの見出しに会わせて作成したものです。
さて、ようやく、このhitachiのDBにcsvファイルをインポートします。
hitachi=# \copy stock from '/stock_db/hitachi.csv' with csv delimiter ',';
これが無事インポートされたかは、以下のコマンドで確認できます。
hitachi=# select * from stock;
以下のようになっていれば、成功です。
これと同じ手続きを、”toshiba.csv”,”jfe.csv”でも行って、”hitachi”,”toshiba”,”jfe”の3つのデータベースを作成してください。
完成すれば、こんな感じになっているはずです。
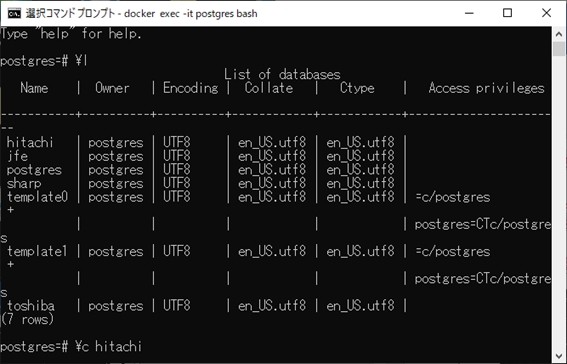
データベースの作成が終了したら、”\q”やら、”exit”やらを打ち込んでいけば、元の画面に帰ってきます。
その後、DBを停止させる場合は、
\money\money1のディレクトリの中から、
$ docker-compose stop
と打ち込んでください。この場合、$ docker-compose startで再起動できます。
ちなみに、
$ docker-compose down
とすれば、コンテナ本体を消滅させることができます。消滅後でも、$ docker-compose -up d で再構築できます。
以上ですが、総じて、Dockerを知らない方にとっては、「チンプンカンプンだった」と思いますし、Dockerの経験者は、「ブサイクな説明だな」と感じたかもしれません。私には、これ以上、「Dockerコンテナを使ったデータベース」と「データベースへのcsvファイルのインポート」を簡単に説明することができませんでした。ご容赦ください。
データベースを(SQL文などを使って)操れるようになると、世界観が変わります ―― パラダイムシフトです。単なる検索やGoogleサーチとは、全く次元の異なるデータの見方が可能となるからです。
『SQLを使い倒して、テロリストグループの周到なマネーロンダリングの流れを突き止めた』という場面が登場する海外ドラマを見たことがありますが ―― 多分、実話をベースにしていると思います。私も、自作のGIS DB(地図情報データベースを使い倒して、その威力を実感しています(筆者のブログ)。
というわけで、ここは一つ、読者の皆さんにも、(面倒でも)データベースを取り扱えるようになって頂きたいと希望しており、今回の記事が、そのきっかけになれば幸いです。
Copyright © ITmedia, Inc. All Rights Reserved.
記事ランキング
- TSMC撤退の逆風越え、浜松に技術者集結――27年GaN内製化へ全力のローム
- ソニーとimec、次世代3D集積向け裏面接続技術を開発
- AIが食い尽くすメモリ供給 企業ITを揺らす価格高騰
- AMDがメモリ最適化技術の新興を買収 「メモリの壁」を打破できるか
- 次世代チップ積層に関する3つの基盤技術を開発
- ソニー初のLOFIC搭載スマホ用画像センサー 飽和電荷量10倍に
- 世界半導体市場が初の単月1000億ドル超え、26年4月
- ソニーが新画素構造「RB2×2 OCL」採用センサー 高解像度とAF性能を両立
- 宙に浮く透明な会議室? 村田製作所の新拠点から見る「オフィスの現在形」
- ADI日本法人新代表が語る「追い風」 AI時代にアナログ半導体が担う役割
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。