ChatGPTは怖くない 〜使い倒してラクをせよ:踊るバズワード 〜Behind the Buzzword(18)(5/11 ページ)
ChatGPTとは何なのか
さて、ChatGPTとは何か、と問われれば、「使えば分かる」と答えれば十分ですが、ここからは、ChatGPTの内部の機能やら学習の方式などについて、私と同様にChatGPTのメカニズムに興味のあるAI研究者、または、ソフトウェア技術者をターゲットとして解説していきます。
まずは、ChatGPTの言葉の意味ですが、これは、Chat Generative Pre-trained Transformerの略です。これを日本語に翻訳すると「事前に訓練された変換機能を使い倒すチャット生成器」という感じになります ―― で、多分、この理解で合っていると思います(後述)。
従来のAIは、「翻訳する」「変換する」「学習する」という機能を使って、「学習した結果、あるいはその学習に沿った結果を吐き出す」という機能がメインでした。これに対して、最近よく耳にするようになった「Generative AI(生成型AI)」というのは、異なるAIの出力結果を混ぜ合わせて、あるいは異なるAI技術の機能を組み合わせて、「未知の新しいものを作り出すAI」という意味で使われています。
で、このChatGPTも、Generative AI(生成型AI)の一つです。ChatGPTを構成するAI技術は以下の3つになります。

このコラムでは、上記3つの技術についての説明はバッサリ省略させていただきます。上記の参考記事の方をご一読いただけますよう、よろしくお願いいたします。私のコラムは、私が私の疑問を解消することが目的でして、徹頭徹尾「江端ファースト」です。
「Over the AI」過去記事
さて、先程申し上げた通り、私の疑問は「なぜ、ChatGPTは、私(たち)に違和感を与えることなく、人間が語る/書くような形式の出力ができるのか」、つまり、「なぜ、良いテキストを生成できるのか」です。この疑問に、技術面からアプローチしてみたいと思います。
そもそも「良いテキスト」とは、どういうものか ―― それは、かなりハッキリしています。「多くの人から『いいね!』と言われるテキスト」です。逆に言えば、品のないツイッターのメッセージ、人を馬鹿にする掲示板の表示などは「悪いメッセージ」と言えます。
そして、このような「良いテキスト」を、ロジカルに説明することは難しく、コンピュータや数式やプログラムには、「良いテキスト」を作り出すことはできない、ということです。ChatGPTの基本形である、GPT-3は、この割り切りからスタートしています(GPT-3については後述します)。
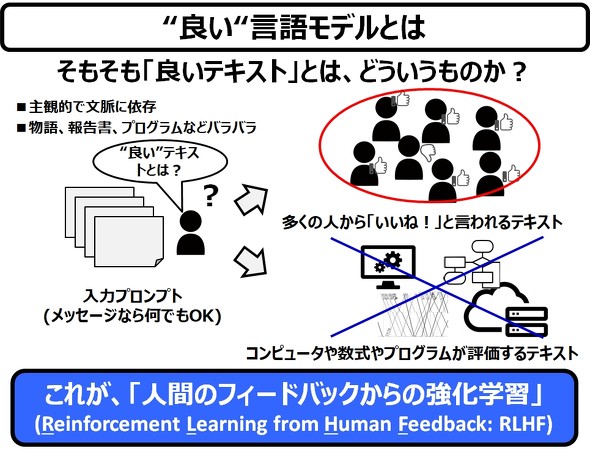
大ざっぱに言えば、これが、人間のフィードバックからの強化学習、Reinforcement Learning from Human Feedback: RLHFです(厳密にはちょっと違いますが、これも後述します)。
さて、このRLHFによって作られるChatGPTのコアエンジン(“本体”という理解でいいです)は、ざっくり3つのプロセスの学習(訓練)によってされます。
Copyright © ITmedia, Inc. All Rights Reserved.
記事ランキング
- ソニーが新画素構造「RB2×2 OCL」採用センサー 高解像度とAF性能を両立
- AIが食い尽くすメモリ供給 企業ITを揺らす価格高騰
- TSMC撤退の逆風越え、浜松に技術者集結――27年GaN内製化へ全力のローム
- 次世代チップ積層に関する3つの基盤技術を開発
- AmazonはNVIDIAに挑戦状を突きつけるのか
- 世界半導体市場が初の単月1000億ドル超え、26年4月
- 車載は「新たな成長段階に」 SiCパワー半導体市場、5年後110億ドル規模へ
- 宙に浮く透明な会議室? 村田製作所の新拠点から見る「オフィスの現在形」
- パッケージ基板の配線微細化と歩留まりを両立させる新製法
- 反りも割れも抑制 先端パッケージ向け多層セラミックコア基板
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。