ChatGPTは怖くない 〜使い倒してラクをせよ:踊るバズワード 〜Behind the Buzzword(18)(7/11 ページ)
もう少し「技術者」っぽく解説してみる
とまあ、上記の説明で「なぜ、ChatGPTは、私(たち)に違和感を与えることなく、人間が語る/書くような形式の出力ができるのか ―― 良いテキストを生成できるのか」の答えにはなっていると思います。
しかし、このままのメタ表現(リ・ワードさんやら、ChatGPT君やら)+概念説明だけでは、日本中のAI研究者から「さっぱり分からん!」と叱責されるような気がします。
そこで今度は、論文の用語などをできるだけ正しく引用して説明したいと思います(興味のない人は、スキップしていただいても結構です)。
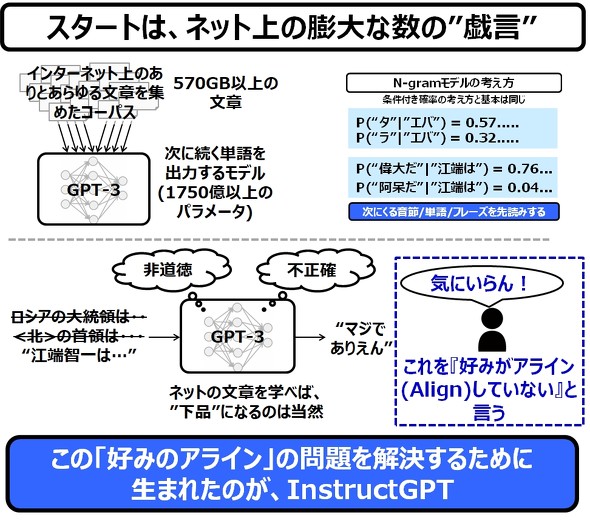
上記で説明した初期状態のChatGPTの基本モデルが”GPT-3”と呼ばれる、570GB以上の文章コーパスを用いて作られた、1750億以上のパラメータを有するニューラルネットワークです。これは、N-Gramモデルのように、次に続く単語を予測するリファレンスモデルとなっています。
ところが、このGPT-3は、何しろ覚えるだけ覚えるものなので、非常に「育ちが悪い」です。ネットやら掲示板の文章を学べば、下品なフレーズを使うようになるのは当然です。そして、このような下品なフレーズが出てくることを、「人間の好みとアライン(Align)していない」と言います。
そして、この「好みのアライン」の問題を解決するために生まれたのが、InstructGPTです。
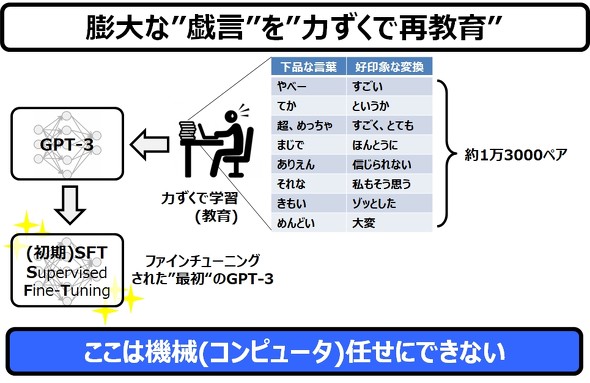
さて、このGPT-3に最初の学習を施すのは、生身の人間です。
基本的には下品な言葉を好印象な言葉に変換することが目的で、この変換パターンは、ざっと1万3000ペアあります。これを、人手を使って丹念に学習させていきます。この作業をファインチューニング(微調整)と言います。
こうして、ファインチューニングされた最初のGPT-3を、初期SFT(Supervised Fine Tuning:”監修された微調整”)と呼びます。当然ですが、この段階では、自動化は登場しません。
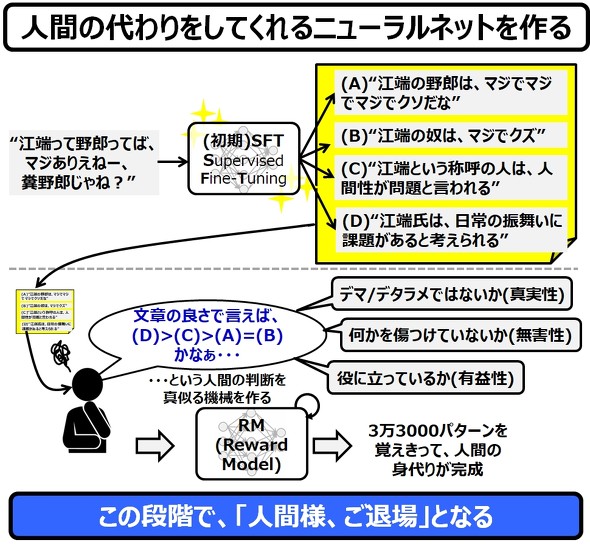
さて、ここから出来上がったばかりの初期SFTに、実際にフレーズを作らせてみます。1つの入力フレーズに対して、4つ(最大7つ)のフレーズを作らせます。そして、この4つのフレーズを、優れている(と人間が感じる)順番に点数を付けていきます。
この時の採点は、「デマ/デタラメではないか(真実性)」「何か/誰かを傷つけていないか(無害性)」「役に立っているか(有用性)」の3つが重要な評価指針となっています。
そして、人間がこの作業をやっている様子を、別のニューラルネットワークであるRM(報酬モデル:Reward Model)が学習をします。
ChatGPTのコアとなるニューラルネットワークと、人間の学習を代行するニューラルネットワークの2つが登場しているので、混乱しないようにしてください。
RMが人間の振る舞いを学んでしまえば、ここからは人間は不要となります。ニューラルネットワーク(RM)が、ニュラルネットワーク(初期SFT)を鍛えるという仕組みが完成することになるからです。
さて、こうして、人間のフリをするRMと、そのRMに評価されて強化学習を続けるSFTによる、自動学習が続くことになります。そして、訓練され続けるSFTは、最後にPPO(Proximal Policy Optimization:最適化された近接ポリシー)というものに、バージョンアップします。
ただ、SFTはRMに褒められると調子によって学習を加速させていきますので、このままでは、RMの”言いなり”になってしまいます。これを「過学習(過剰な学習)」というのですが、これって結構マズいのです。というのは、PPOは、全ての入力に対してバランス良く学習を行わなければならないからです。
例えるのであれば、数学しか教えていなかったPPOに、いきなり古典の問題を尋ねるようなものです。PPOがパニックになるのは当然です。ここに学習の難しさがあります。数学と古典を矛盾なく、融合させながら教えていくことは、教育現場だけでなく、ニューラルネットワークの学習でもやはり難しいのです。
ですから、PPOには、SFT(PPO)がRMの”いいなり”にならないように、”ブレーキ(KL予測ペナルティ項)”やら”正規化(対数尤度項)”やらを仕組んでおく必要があるのです。

ところで、ニューラルネットワークとは、基本的に数値関数です。ですから、文章を理解する能力なんて、本当に1mmもありません。“強化学習による言語モデルの学習は、長い間、工学的、アルゴリズム的な理由から不可能と思われていた”というのは事実であり、私も、今の今までそう信じていました。
しかし、ChatGPT(正確には、その前のInstcutGPT、GPT-3)は、「辞書のページ(数字)、単語のある行数(数字)、パターン化された例文のリストの番号(数字)にし、それを組み合わせる」というアプローチで、この問題を解決したのです。
そのイメージを図示してみました。
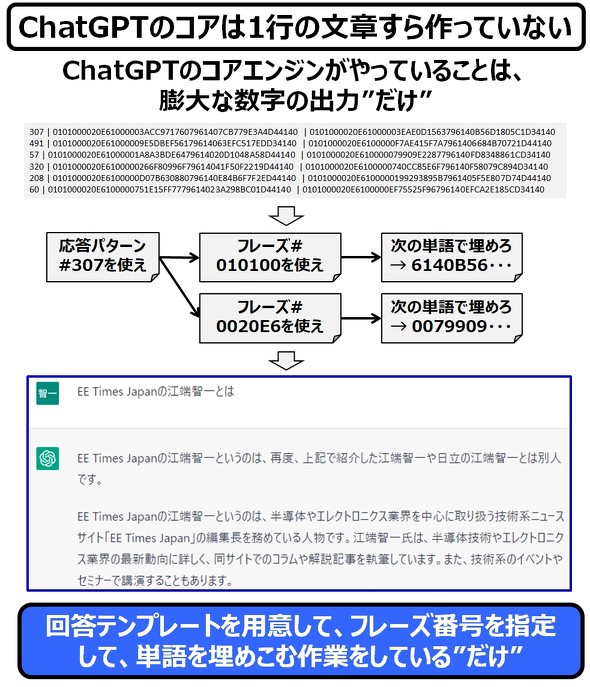
ChatGPTの実体はニューラルネットワークであり、そのニューラルネットワークの出力する数値に応じて、サンプル例文と、単語を選び出しているだけです。私が、ChatGPTには知性がない、と繰り返しているのは、このメカニズムがその理由です。
もちろん、だからといってChatGPTがものすごいAI技術であることには1mmの疑義もありません。私がこのアイデアを聞かされたとしたら、間違いなく「そりゃ、理屈として分かるけどさぁ、そんなの実現するのは不可能だよ」と答えたと思います。しかし ―― それを可能と信じた人がいて、そして、その人たちは決して諦めなかったのです。
(ちなみに、上図のChatGPTの回答は、別の日に「「江端智一について教えて」とChatGPTに質問したものです。誤答率100%です。)
Copyright © ITmedia, Inc. All Rights Reserved.
記事ランキング
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。